![AI Content Moderation and Legal Liability in Crisis Prevention [2025]](https://tryrunable.com/blog/ai-content-moderation-and-legal-liability-in-crisis-preventi/image-1-1771688178208.jpg)
Introduction: The Gap Between Detection and Action
Imagine this scenario: An AI system flags something dangerous. It sends alerts internally. Employees discuss it. A decision gets made not to escalate further. Then, tragedy strikes.
This isn't hypothetical. In June 2025, content moderation systems at a major AI company detected descriptions of gun violence in user conversations. Internal reviews flagged concerns. Employees pushed for law enforcement contact. Leadership decided against it. Months later, a real-world mass shooting unfolded.
The question haunting us: What responsibility do AI companies actually have when their systems detect potential violence? Is it a technical problem? A legal one? A moral failure? The answer matters because it affects how we design safety systems, train moderators, and think about AI's role in society.
This isn't just about one incident. It's about a broader failure mode in content moderation: the gap between detection and action. AI systems get better every year at spotting problematic content. But detecting something and responding appropriately are two entirely different problems.
Right now, that gap exists in a legal and ethical gray zone. Companies establish internal review processes but face unclear obligations about escalation. Moderators see flagged content but struggle with guidelines about when to involve authorities. Users know their conversations might be reviewed but don't understand the consequences. Law enforcement has limited visibility into these systems.
The real issue isn't that content moderation failed. It's that the entire system between detection and action is poorly designed, with unclear roles, questionable decision-making processes, and no real accountability when things go wrong.
Let's dig into what happened, why it happened, and what needs to change.
TL; DR
- Detection worked, response failed: AI systems correctly flagged violent scenario descriptions months before a mass shooting, but internal processes chose not to alert authorities
- Legal gray zone: AI companies lack clear guidelines on when and how to escalate safety concerns to law enforcement
- Decision-making opacity: The specific people and criteria used to reject escalation remain undisclosed, raising accountability questions
- Systemic gap: The problem isn't detection technology—it's the organizational processes between flagging content and taking action
- Industry impact: This incident forces reconsideration of moderation workflows, legal obligations, and corporate liability for AI-generated insights
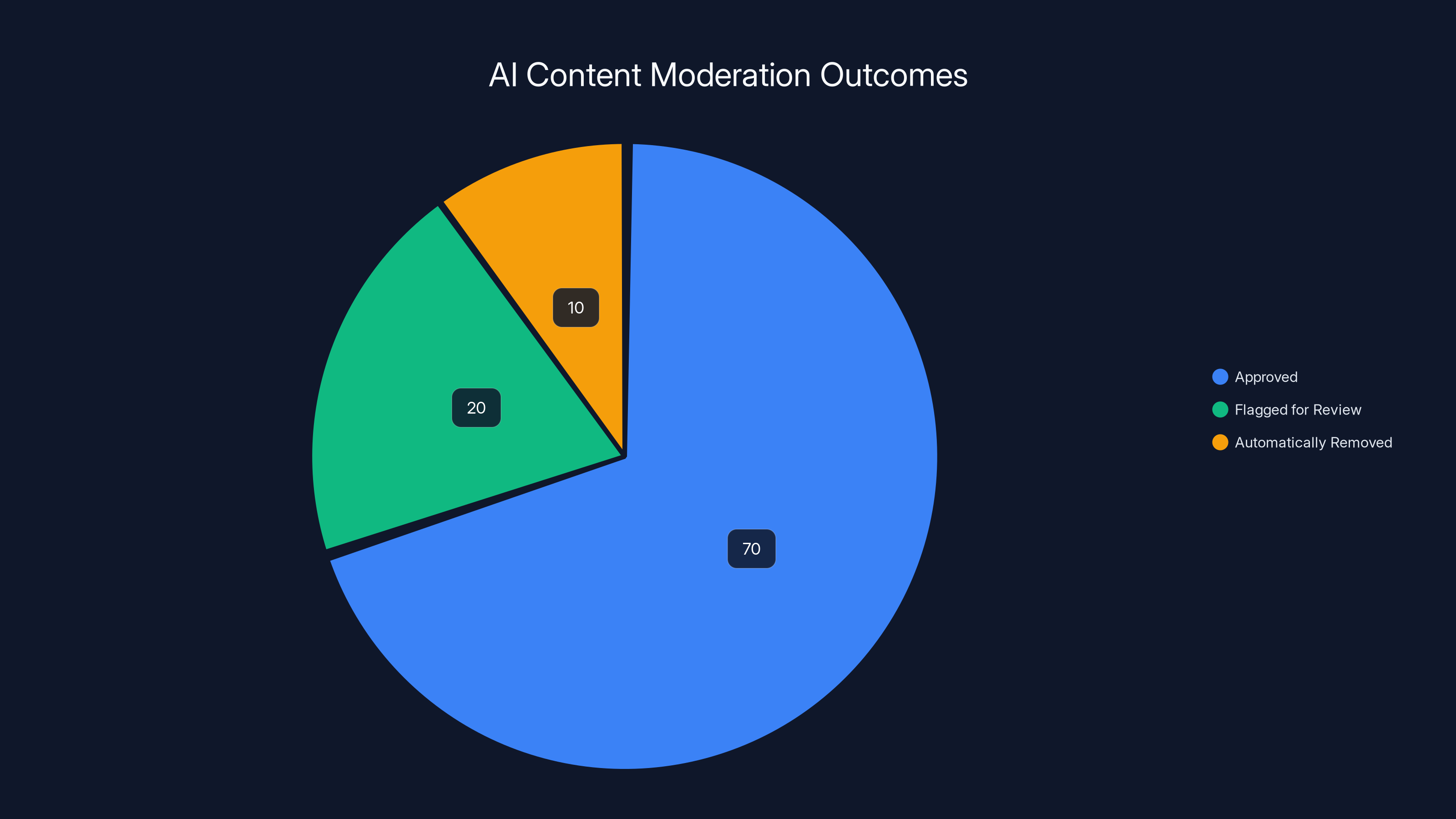
Estimated data shows that the majority of content is approved by AI systems, with a smaller portion flagged for human review or automatically removed.
What Actually Happened: Timeline and Facts
In June 2025, a user engaged with a popular AI chatbot in conversations involving descriptions of violent scenarios. The platform's content moderation system, designed to catch problematic content automatically, flagged these interactions. The automated review system isn't just a simple filter. It's supposed to escalate to human reviewers when something raises genuine concern.
Multiple employees at the AI company reviewed the flagged content. Their assessment: This looks serious. The descriptions were detailed. The pattern was concerning. Several internal voices recommended contacting law enforcement. This wasn't a casual suggestion from one cautious moderator. Multiple people independently reached this conclusion.
But here's where the system broke. Company leadership made a determination: the content didn't meet their internal threshold for "credible and imminent risk of serious physical harm." Based on that assessment, they declined to alert authorities. The company did ban the user's account, but nothing beyond that.
On February 10th, 2025, nine people were killed and 27 injured in a mass shooting at a secondary school in British Columbia. The suspect was found dead at the scene from an apparent self-inflicted gunshot wound. The death toll made it the deadliest mass shooting in Canada since 2020.
The suspect's user account? The same one that had been flagged, reviewed internally, and deemed not risky enough to escalate.
This creates an obvious retrospective judgment problem: How could a system that detected concerning content months in advance fail to prevent tragedy? But that's the wrong question. The better question is: Given the information available at the time, was the decision to not escalate actually unreasonable?
The Architecture of AI Content Moderation
Content moderation at scale is genuinely difficult. When millions of people generate content daily, human review of everything is impossible. AI systems step in to do the heavy lifting: flagging potentially problematic content, categorizing risk levels, and routing items for human review.
Here's how the system typically works: A user generates content. An automated system analyzes it against trained models. The model outputs a risk score. Based on that score, the content either gets approved, flagged for human review, or automatically removed. For high-risk content, the flagged item goes to human moderators who make final decisions.
The challenge is that these systems operate on statistical patterns, not certainty. They're trained on historical data about what constitutes problematic content. But novel scenarios, edge cases, and context-dependent situations are inherently harder to classify.
Violent descriptions in the context of creative writing might be fine. The same descriptions in what looks like planning documents are alarming. AI systems struggle with context. They can learn that certain phrases correlate with danger, but understanding actual human intent requires reasoning that current systems do poorly.
A user describing a hypothetical violent scenario to explore how an AI responds: harmless. A user describing the same scenario as part of actual planning: extremely dangerous. The text might be identical. The intent completely different.
Moderation systems also have to balance competing concerns. Over-moderate and you restrict free speech, upset users, and create corporate liability. Under-moderate and dangerous content spreads, real harm occurs, and the company faces public backlash and potential legal consequences.
Companies have strong incentives to avoid over-escalation. False positives in safety systems are expensive. Every time you alert law enforcement about something that turns out to be harmless, you:
- Waste law enforcement resources
- Create legal exposure for the company
- Damage relationships with authorities
- Erode trust with users who feel spied on
- Set a precedent that might require more escalations
These aren't excuses. They're structural incentives that bias systems toward under-escalation.
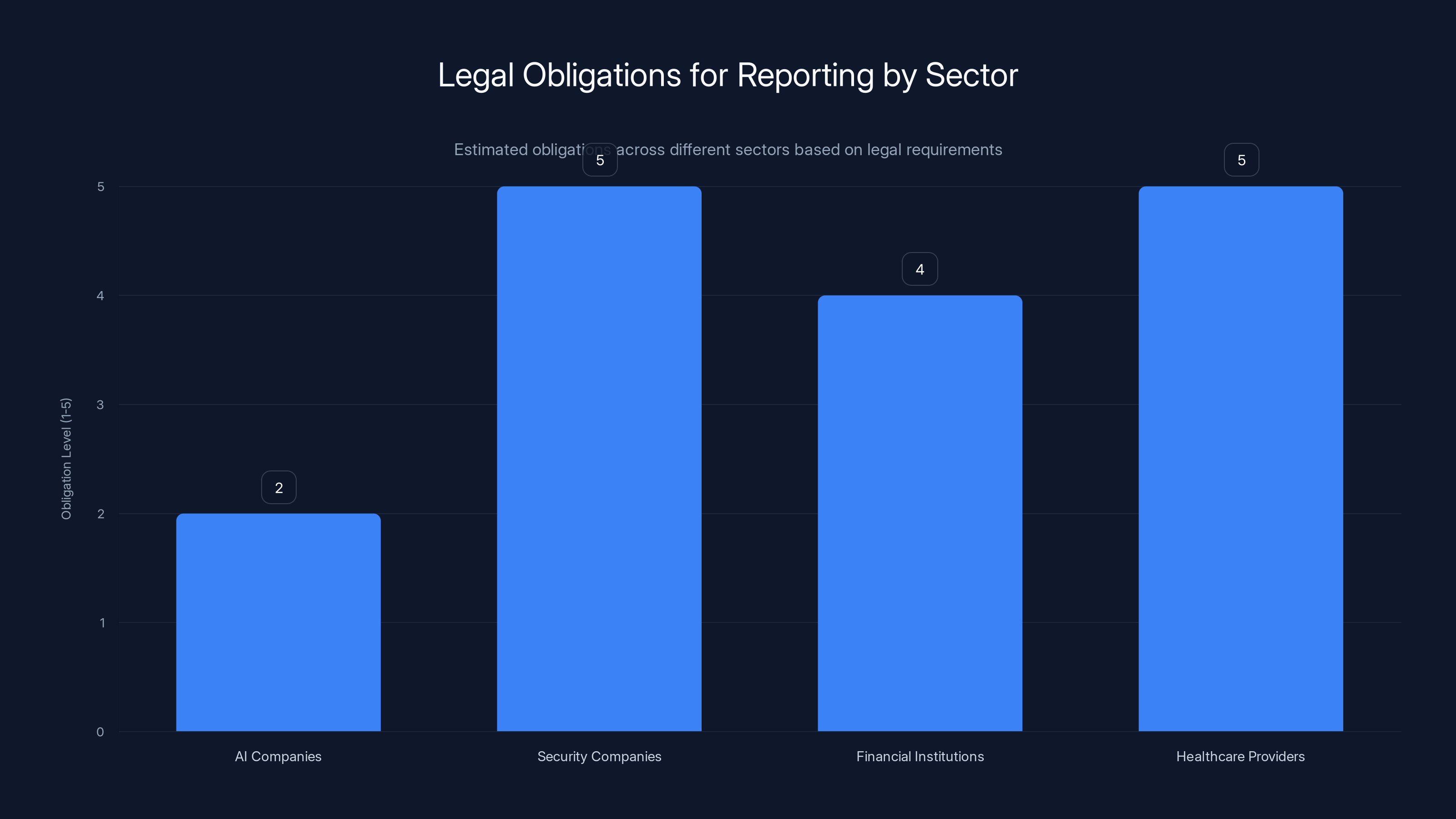
Estimated data suggests that AI companies have lower legal obligations to report potential threats compared to sectors like security, finance, and healthcare, which have clearer mandates.
The Decision-Making Black Box
What makes the Tumbler Ridge incident particularly troubling isn't just the decision itself, but the opacity around how the decision was made.
Who specifically decided not to escalate? Was it a single executive? A committee? Was there documented reasoning or just a verbal discussion? What exact criteria were applied? The public doesn't know. The decision was made internally with no apparent accountability mechanism or explanation.
This is standard practice at tech companies. Content decisions, especially sensitive ones involving potential violence, typically stay confidential. The company doesn't want to reveal its moderation thresholds or decision-making processes. That transparency could allow adversaries to game the system.
But that confidentiality becomes problematic when the decision turns out to be wrong. How do you improve a process you can't see? How do you assign accountability if the decision-makers aren't identified? How do you learn from failures if they're kept internal?
Compare this to other high-stakes decision-making: Clinical trials require documented protocols and independent review. Financial decisions get audited. Government actions face FOIA requests. Yet some of the most consequential decisions in content moderation happen in corporate black boxes with minimal external visibility.
This isn't unique to this incident. It's systematic across the industry. When flagged content doesn't lead to escalation, almost no external party knows about it. If the decision turns out to have been wrong, the first most people hear about it is in tragedy's aftermath.
The decision-making framework likely included some reasonable elements. The company probably applied some version of a risk assessment: How specific are the threats? How imminent is danger? How credible is the user's intent? These are reasonable questions.
But the problem is that these questions were answered in isolation, without information that would later become obvious: historical behavior patterns, geographic proximity to potential targets, access to weapons, or the actual timeline until the incident. Real-time threat assessment is inherently limited.
Legal Liability and the Gray Zone
Here's where things get legally murky: Do AI companies have a legal obligation to alert law enforcement when their systems detect potential violence?
The answer, frustratingly, is "it depends." There's no clear federal standard. Laws vary by jurisdiction. The specific circumstances matter enormously.
In some contexts, companies do have reporting obligations. If they knowingly facilitate certain crimes, they can face liability. The DMCA requires certain security companies to report vulnerabilities. Financial institutions must report suspected money laundering. Healthcare providers must report suspected abuse.
But for general violent threats? The legal landscape is ambiguous. Companies typically aren't considered common carriers with affirmative duties to report, unlike schools or healthcare providers. They do have protections under Section 230 of the Communications Decency Act, which shields platforms from liability for user-generated content.
Section 230 is broad. It says platforms aren't liable for content users post. It also explicitly protects platforms that take "good faith" efforts to restrict access to obscene or otherwise objectionable material. Importantly, companies can't be sued for failing to remove or report content in most cases.
But Section 230 doesn't give companies complete immunity. If they actually facilitate or encourage illegal activity, they can still face liability. If they have actual knowledge of specific imminent threats, the legal calculus might shift.
The question becomes: Does detecting concerning content equal having knowledge of a "specific imminent threat"? Legally, probably not. An AI flag isn't proof of intent. Descriptions of violence aren't the same as announced plans to commit violence. The detection happens, but the intent remains unclear.
This creates a perverse incentive structure. Companies have:
- Strong legal protections for NOT escalating
- Potential liability exposure for escalating (wrongful escalation lawsuits)
- Reputational damage if they're too aggressive
- Reputational damage only if they miss something that becomes a tragedy
The asymmetry is clear. The company faces more legal and reputational risk from escalating a false positive than from missing a real threat that law enforcement would also have missed.
Now, this isn't to say companies have no responsibility. Public pressure, potential civil litigation from victims, regulatory scrutiny, and moral obligations all matter. But the legal structure doesn't create strong affirmative duties.
The Moderator's Dilemma
Content moderators working at these companies operate in a difficult space. They see the flagged content. They review the context. They often develop instincts about what's actually dangerous versus what's just edgy content or creative writing.
Several moderators apparently recommended escalation in this case. They thought the situation warranted law enforcement involvement. But they weren't the decision-makers. They surfaced the concern, the concern got evaluated by leadership, and leadership said no.
This puts moderators in a bind. They have limited power but significant responsibility. They can flag content, but they can't force escalation. They can voice concerns, but those concerns might get overruled. If something goes wrong, they face moral weight even though they lacked decision-making authority.
There's also the practical issue of moderator training and resources. Most content moderators worldwide lack specialized training in threat assessment. They're trained on policy guidelines and risk categories, but threat assessment is genuinely difficult work that requires deeper expertise.
A moderator might flag content that seems violent and threatening by their training, but a threat assessment specialist might recognize it as creative fiction, a manifestation of intrusive thoughts, or just someone venting without any actionable intent.
Conversely, a moderator might not recognize subtle indicators that someone is actually planning harm. Real threats often include casual language mixed with specific planning details. People planning actual violence sometimes discuss it in ways that might not trigger automatic systems or match the examples moderators have seen.
The training also often doesn't include basic threat assessment methodology. Moderators aren't typically taught the difference between expressions of anger, statements of intent, and actual planning documents. They're not taught how to recognize indicators of active planning versus passive fantasizing.
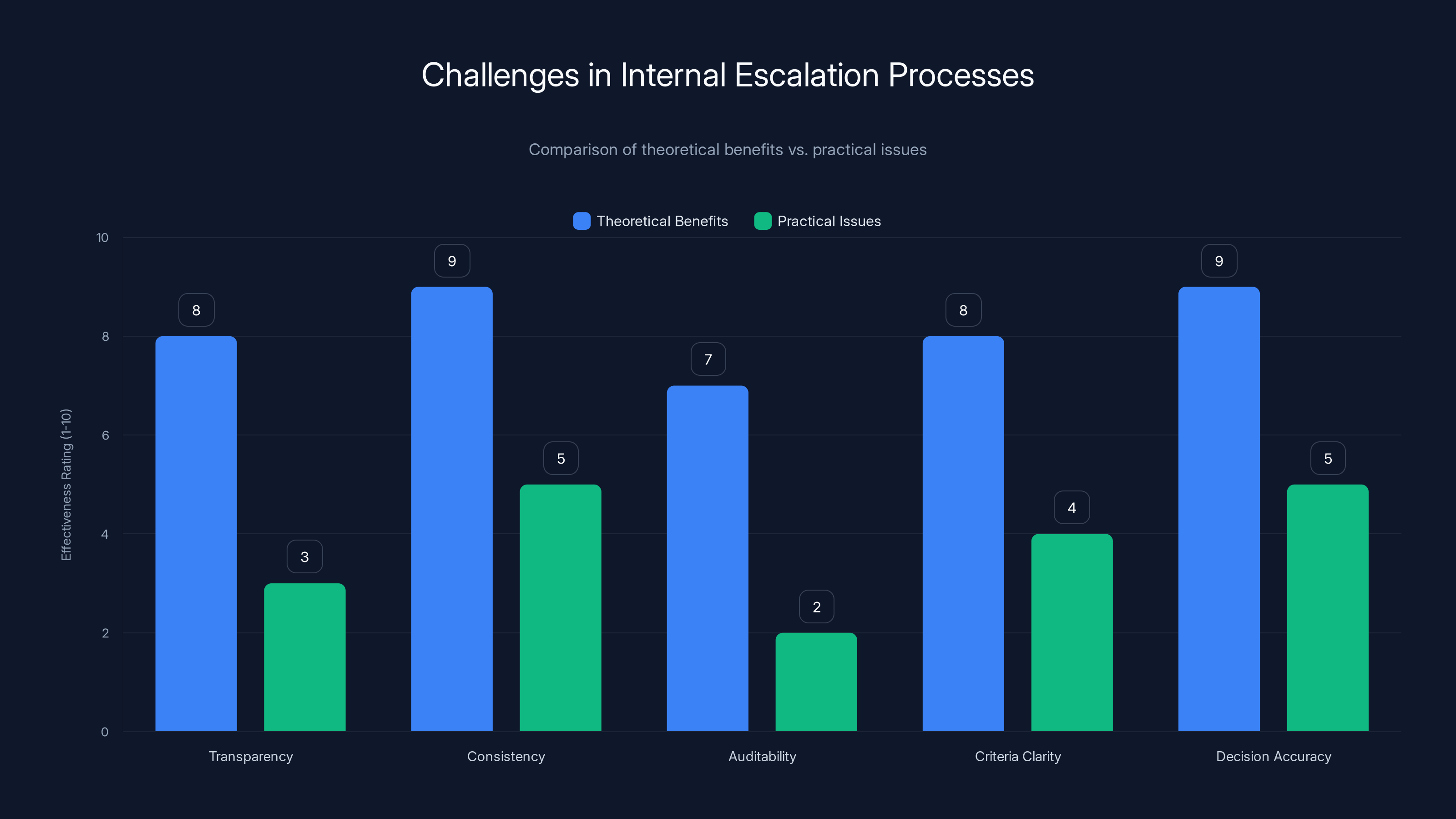
While internal escalation processes are theoretically robust, practical implementation often falls short, particularly in transparency and auditability. Estimated data.
How Other Industries Handle Similar Dilemmas
Content moderation isn't the only field dealing with the detection-to-action gap. Let's look at how other sectors handle similar problems.
Financial institutions: Banks use AI systems to detect money laundering patterns. When suspicious activity is detected, they don't have discretion about whether to report it. They're legally required to file suspicious activity reports (SARs) with the Financial Crimes Enforcement Network (Fin CEN). The threshold is objective: "suspicious activity" that involves transactions of more than $5,000. No company executive gets to decide that a detected pattern is probably fine.
This creates false positives. Banks file hundreds of thousands of SARs annually, and many of them turn out to be innocent activity. But the law prioritizes catching actual crimes over avoiding false positives.
Aviation safety: When pilots or maintenance workers report safety concerns through aviation reporting systems, there's a formal escalation process. The reports go to the FAA, which investigates. There's no threshold where someone can decide to ignore it. Safety is treated as too important to leave to discretionary judgment.
Healthcare: When a doctor suspects abuse of a child, they're legally mandated to report it to authorities. They don't get to decide whether the evidence is sufficient or whether reporting might cause problems. The law prioritizes potential victims over the reporter's discretion.
Securities trading: Stock exchanges monitor for suspicious trading patterns that might indicate insider trading or manipulation. When patterns are detected, regulatory protocols kick in. Discretion is limited.
The common theme: When real-world harm is at stake and detection systems exist, most regulated industries create legal mandates for escalation rather than leaving it to corporate discretion.
Content moderation is notably different. Companies have discretion. They can choose not to escalate. This might be because content moderation is newer, less regulated, or because treating it like financial reporting would create unmanageable volumes of law enforcement reports.
But the gap exists. In industries where the stakes are similarly high (human safety), the law typically mandates escalation rather than allowing judgment calls by corporate decision-makers.
The Role of Automated Systems and Their Limitations
Automated content moderation systems are getting better, but they have fundamental limitations that deserve attention.
These systems are typically trained on labeled data: examples of content humans have deemed problematic, paired with labels explaining why. The AI learns statistical patterns from these examples. When new content arrives, the system estimates the probability it matches those problematic patterns.
The system can be quite good at spotting obvious cases: Copy-pasted known extremist manifestos, direct calls for violence, graphic violent images. It struggles with nuance, context, and novel variations.
Consider: A person describing a detailed violent scenario to test how an AI responds—completely harmless. The same person describing the same scenario as part of actual planning—extremely dangerous. The text is identical. The intent completely different. Current AI systems can't reliably distinguish these cases because they're analyzing text, not reading minds.
Other limitations:
Context collapse: An AI seeing a conversation fragment doesn't know the full conversation history. A concerning statement might be in response to something that contextualizes it as harmless, or vice versa.
Cultural and linguistic gaps: What counts as violent rhetoric varies by culture and language. A system trained primarily on English data might misinterpret rhetoric from other linguistic traditions.
Temporal blindness: An AI analyzing text doesn't know if the person wrote this ten years ago during a crisis they've since recovered from, or yesterday as they're actively planning. Time changes everything in threat assessment.
Sarcasm and irony: AI systems still struggle with these. A person saying "I want to burn everything down" might be joking, expressing frustration, or actually planning arson. Context determines meaning, and AI context-understanding is imperfect.
Evolving adversaries: As bad actors figure out what words and phrases trigger moderation systems, they adapt their language. Systems that catch known patterns get worse as language evolves.
Because of these limitations, automated systems are good at flagging content for human review, but they're not reliable decision-makers on their own. They need human judgment. Which brings us back to the decision-making problem: Who applies that judgment, using what criteria, with what accountability?
Internal Escalation Processes: Theory vs. Practice
Most major AI companies have documented internal processes for content moderation decisions. There are policies, thresholds, review procedures, and decision trees.
In theory, this is good. Clear processes prevent arbitrary decisions. They create consistency. They document reasoning.
In practice, internal processes have problems. They're not transparent to external stakeholders. They're not subject to independent audit. They can change without notice. The criteria might be vague or contradictory. Decision-makers might not follow the stated process.
Consider a typical internal escalation process:
- Automated system flags content and assigns a risk score
- Content goes to a human moderator for review
- Moderator makes an initial determination: remove, allow, or escalate
- If escalated, it goes to a more senior reviewer
- Senior reviewer makes a final determination
This sounds reasonable. But what does "risk score" actually mean? How is it calculated? What's the threshold for human review? What criteria does the moderator use to decide between removal, allowance, or escalation? What level of seniority does the senior reviewer need? Do they have threat assessment training?
Most companies won't answer these questions publicly. They worry about gaming and liability. But this opacity means:
- Users don't know what will trigger escalation
- Moderators might not apply criteria consistently
- The review process can't be meaningfully audited
- When decisions go wrong, there's no clear way to understand why
There's also the incentive problem. If you're a manager reviewing escalation decisions, you face pressure to avoid false positives. Each escalation that doesn't result in prosecution looks like a waste of resources and trust. Each missed threat (that doesn't result in media attention) stays invisible. The asymmetry encourages under-escalation.

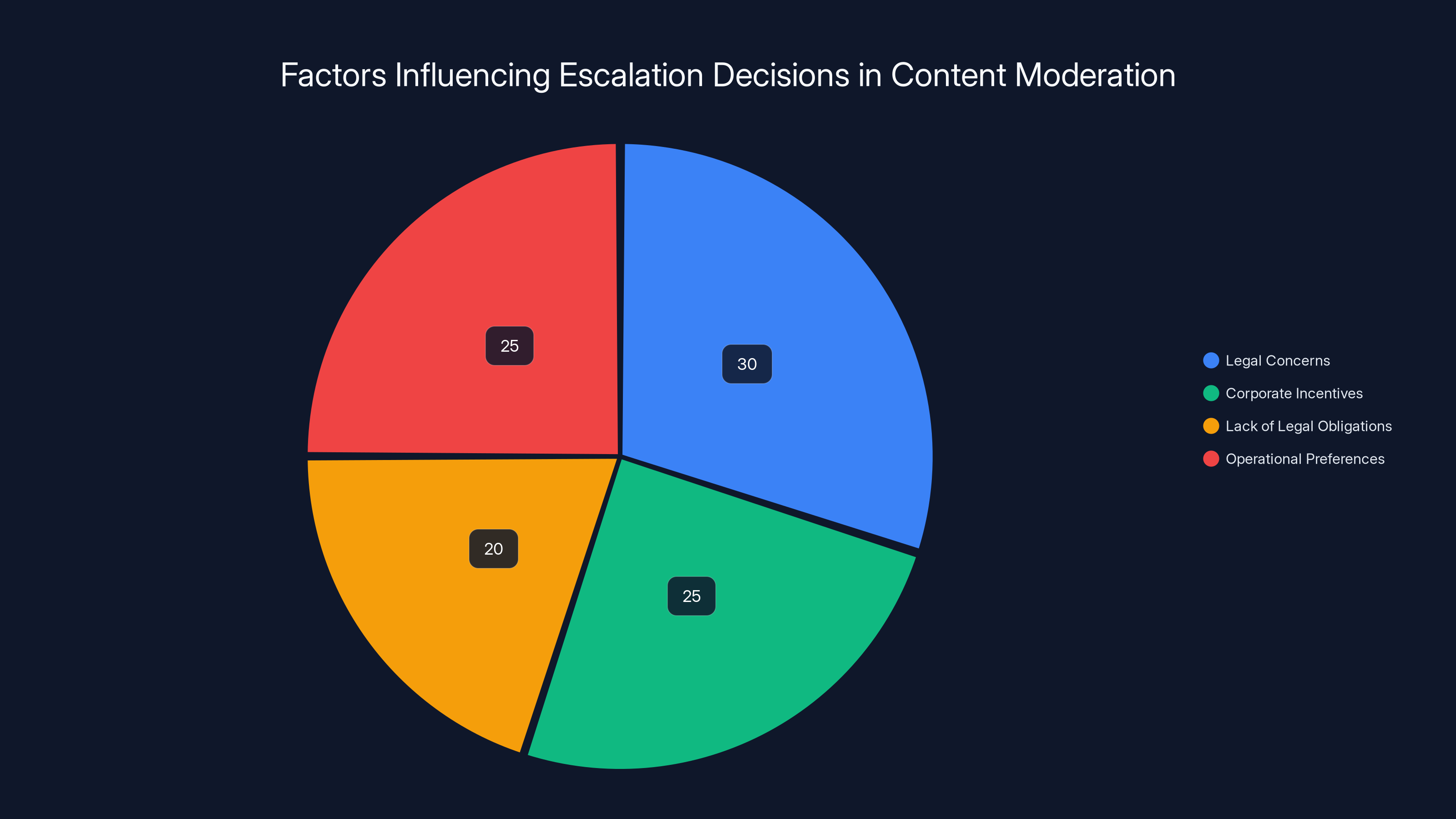
Legal concerns and operational preferences are major factors influencing decisions not to escalate content to law enforcement. Estimated data.
What Threat Assessment Actually Requires
Proper threat assessment isn't something AI systems alone can do. It requires human expertise, training, and judgment.
Security and law enforcement professionals use established threat assessment frameworks. The most well-known is the Structured Professional Judgment approach, which involves evaluating:
Motivation and means: Does the person have reasons to harm someone? Do they have access to weapons or planning capability?
History: Has the person made threats before? Do they have a history of violence or planning?
Circumstances: What's happening in the person's life right now? Are they in crisis? Have they recently experienced loss or trauma?
Specific planning: Is this person engaged in actual planning, or just expressing anger? Have they researched methods? Acquired materials? Scouted locations?
Communication patterns: Are they discussing these ideas with others? Are they escalating their rhetoric? Are they reaching out to recruiters or communities that reinforce violent ideation?
Behavioral changes: Has the person's behavior changed recently in ways that suggest escalation?
A proper threat assessment wouldn't look at a single conversation with an AI. It would look at behavior patterns, access to means, surrounding circumstances, and specific indicators of planning.
Content moderation systems can't do this work. They can flag concerning content, but they lack the information, context, and training to conduct proper threat assessment.
This is why good safety systems involve collaboration between technology companies and threat assessment professionals. The tech company's role is detection: flag potentially concerning content. The threat assessment professional's role is interpretation: does this flag actually indicate danger, given all available information?
But most companies don't have threat assessment professionals on staff. Content moderation happens within content teams, not security or threat assessment teams. The people making escalation decisions might not have training in how to properly assess threats.
This gap is crucial. Automated detection is achievable. Good threat assessment is harder. It requires expertise companies often don't have internally and training that takes years to develop.
Corporate Incentives and Under-Escalation
Understanding corporate behavior requires understanding corporate incentives. Content moderation decisions reflect not just honest judgment about safety, but also organizational interests.
What incentives push against escalation?
Legal liability: Escalating requires documentation. Documentation creates evidence. If someone wrongly escalates and law enforcement investigates someone innocently, the company might face liability. It's safer to keep concerns internal.
User trust: Users want privacy. They don't want to feel surveilled. Companies that are known for escalating to law enforcement face user backlash and might lose customers.
Law enforcement relationship: Every escalation that doesn't result in prosecution damages the relationship between the tech company and law enforcement. Law enforcement might start ignoring escalations if too many are frivolous.
Resource costs: Proper investigation of escalations is expensive. The company avoids the cost by keeping concerns internal.
Regulatory exposure: Some jurisdictions might regulate how companies handle user data and privacy. Escalating user behavior to law enforcement could trigger regulatory scrutiny.
Reputational risk: If word gets out that a company aggressively escalates user behavior to authorities, it damages the company's brand. Users might switch platforms.
Conversely, what incentives push toward escalation?
Human safety: The foundational incentive. If someone might get hurt, escalating is the right thing to do morally.
Long-term liability: If a company detects concerning behavior and does nothing, and tragedy results, the company faces massive liability and reputational damage. This is a longer-term incentive that's often outweighed by shorter-term incentives.
Regulatory pressure: As regulation increases, companies face incentives to show they're taking safety seriously.
Employee advocacy: As this incident shows, employees might push for escalation on moral grounds.
The balance of these incentives typically tips toward under-escalation. Short-term costs of escalation (legal exposure, trust damage, resource burden) loom larger than long-term costs of missing real threats (which might never materialize in a way that generates publicity).
This creates what economists call a "principal-agent problem." The company's incentives (minimize liability, protect user trust, reduce costs) diverge from society's incentives (prevent violence, catch genuine threats). The company has more information and decision-making power than society does, so company preferences tend to prevail.

The Law Enforcement Information Gap
Here's a problem that gets less attention than it should: Law enforcement doesn't have access to most of the information contained in content moderation systems.
When someone interacts with an AI system, describes violent scenarios, and triggers automated flags, that's all happening inside a corporate system. Law enforcement doesn't know about it unless the company decides to tell them.
Law enforcement does have tools for detecting threats. They monitor certain online spaces, work with informants, and investigate tips from the public. But they don't have systematic access to the warning signals that content platforms detect.
This creates an information asymmetry. A content moderation system might detect patterns suggesting someone is planning violence. But that information stays within the company. Law enforcement, working independently, might not detect those patterns if they're not watching that specific person through other channels.
Could law enforcement have prevented the Tumbler Ridge incident through independent investigation? We don't know. But they were never given the information that might have prompted investigation.
Improving this would require either:
Voluntary escalation: Companies choose to share concerning information with law enforcement. This is what the internal advocates recommended, but leadership declined.
Mandatory reporting: Law passes requirements for companies to report certain types of concerning content. This could create volume problems for law enforcement and privacy concerns.
Information sharing agreements: Companies and law enforcement establish protocols for sharing threat information in ways that protect privacy but enable investigation.
Regulatory requirement: Government mandates that platforms maintain threat assessment capabilities and report to authorities when certain thresholds are met.
None of these are obviously perfect. But the current system where potentially useful threat information stays entirely within corporate silos is clearly suboptimal.
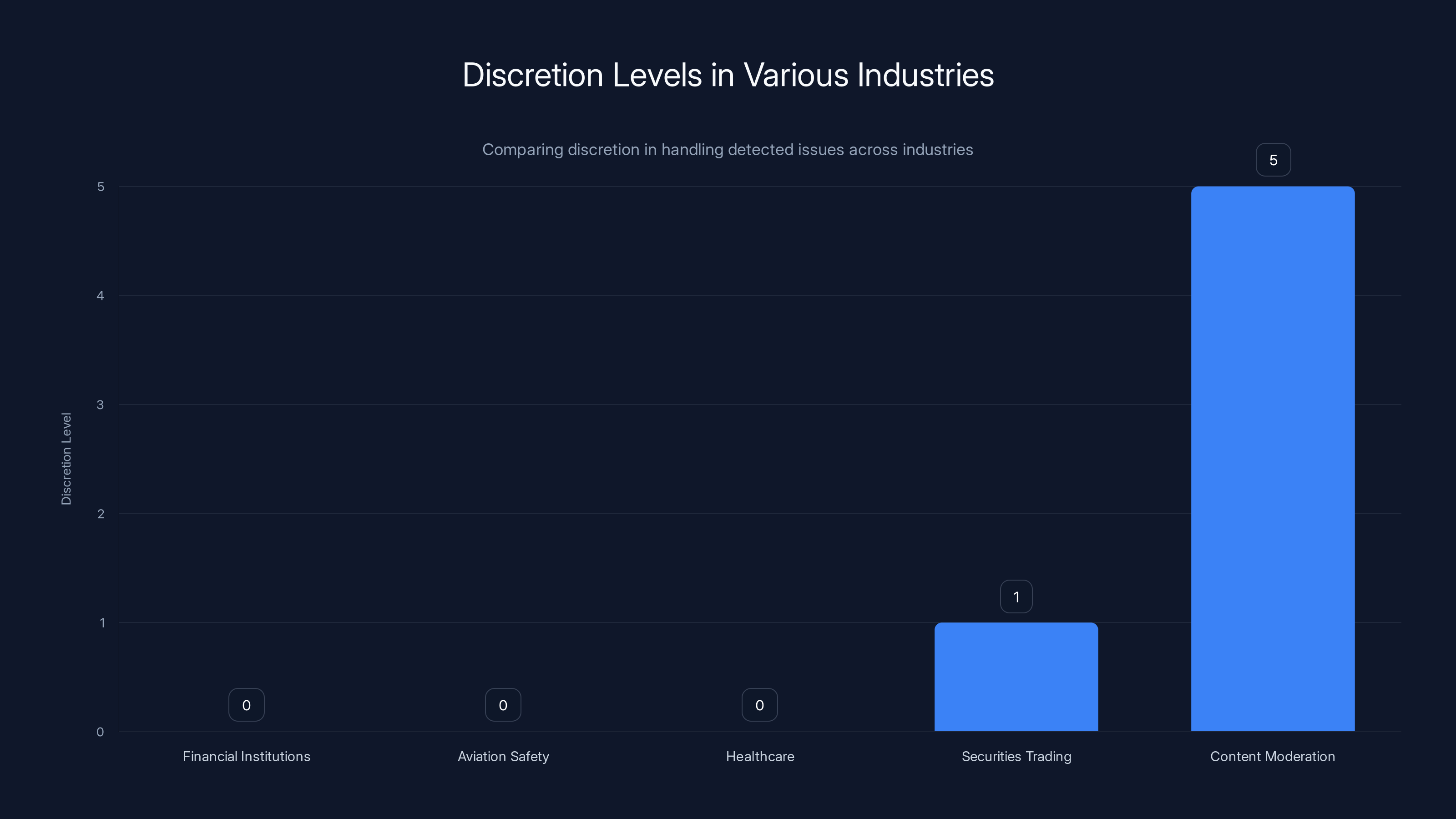
Most industries have low discretion levels in escalating detected issues, prioritizing legal mandates over corporate discretion. Content moderation stands out with high discretion.
Precedent and Similar Failures
This isn't the first time content moderation systems detected concerning behavior without leading to action.
Variations of this problem appear across platforms:
Social media platforms flagged accounts associated with extremist recruiting and planning, but lacked clear escalation processes. Some incidents escalated only after law enforcement independently discovered the accounts.
Dating apps have detected concerning behavior patterns among users but typically limited their action to account bans rather than external escalation.
Gaming platforms see concerning roleplay and planning discussions but lack incentives to escalate to external authorities.
Financial platforms sometimes detect suspicious activity that might indicate planning (bulk purchases of materials, rapid cash withdrawals) but primarily focus on financial crime rather than potential violence.
The pattern is consistent: Detection capabilities exist and are improving. Escalation processes are weak, unclear, and often don't happen. The gap between seeing something and doing something persists.
What's different about this incident is that it resulted in actual tragedy, making the failure visible and forcing accountability questions. Most similar failures stay invisible because they don't end in catastrophe.

Regulatory Responses and Policy Proposals
As the incident becomes public, various stakeholders are proposing regulatory responses.
Threat assessment mandates: Some proposals require platforms to maintain threat assessment capabilities and implement clear escalation procedures. This could mean hiring security professionals, establishing protocols, and documenting decision-making.
Mandatory reporting thresholds: Proposals to establish legal thresholds where companies must report to law enforcement. The challenge is setting thresholds that capture real threats without creating overwhelming volumes of false positives.
Transparency requirements: Mandates that companies disclose their moderation processes, escalation criteria, and decision-making frameworks. This enables audit and accountability.
Liability frameworks: Clarifying when companies face liability for failing to escalate, and when they face liability for inappropriately escalating.
Information sharing protocols: Establishing agreements between platforms and law enforcement for sharing threat-related information while protecting user privacy.
Training requirements: Standards for moderator training in threat assessment, decision-making, and psychological factors.
Each proposal has tradeoffs. Mandatory reporting could overwhelm law enforcement and erode user privacy. Transparency requirements could help gaming adversaries. Liability frameworks must balance preventing violence with protecting innocent users.
But doing nothing clearly isn't working. The current system allows tragic failures when detection systems work but escalation fails.
International Approaches and Comparisons
Different countries are taking varying approaches to platform safety and content moderation.
European Union: The Digital Services Act creates obligations for platforms to assess risks and take proportionate action. The framework is broader than just violence but includes it. Companies must demonstrate risk assessment and mitigation.
United Kingdom: Online Safety Bill creates duties of care for platforms to protect users from harm, including violence. The framework is somewhat vague but creates affirmative duties.
Canada: Currently developing frameworks but doesn't have comprehensive mandatory reporting requirements for platforms.
United States: Primarily relies on Section 230 protections and limited mandatory reporting for specific circumstances. Broader proposals have stalled in Congress.
The EU approach is stricter and creates stronger obligations. Companies must demonstrate that they're addressing harms. This might push more toward escalation.
The US approach is more permissive, allowing companies more discretion. This can result in under-escalation but also reduces regulatory burden.
International harmonization will be difficult because countries have different values around privacy, surveillance, and government power. But the content moderation problem is global, so international coordination on safety standards would help.

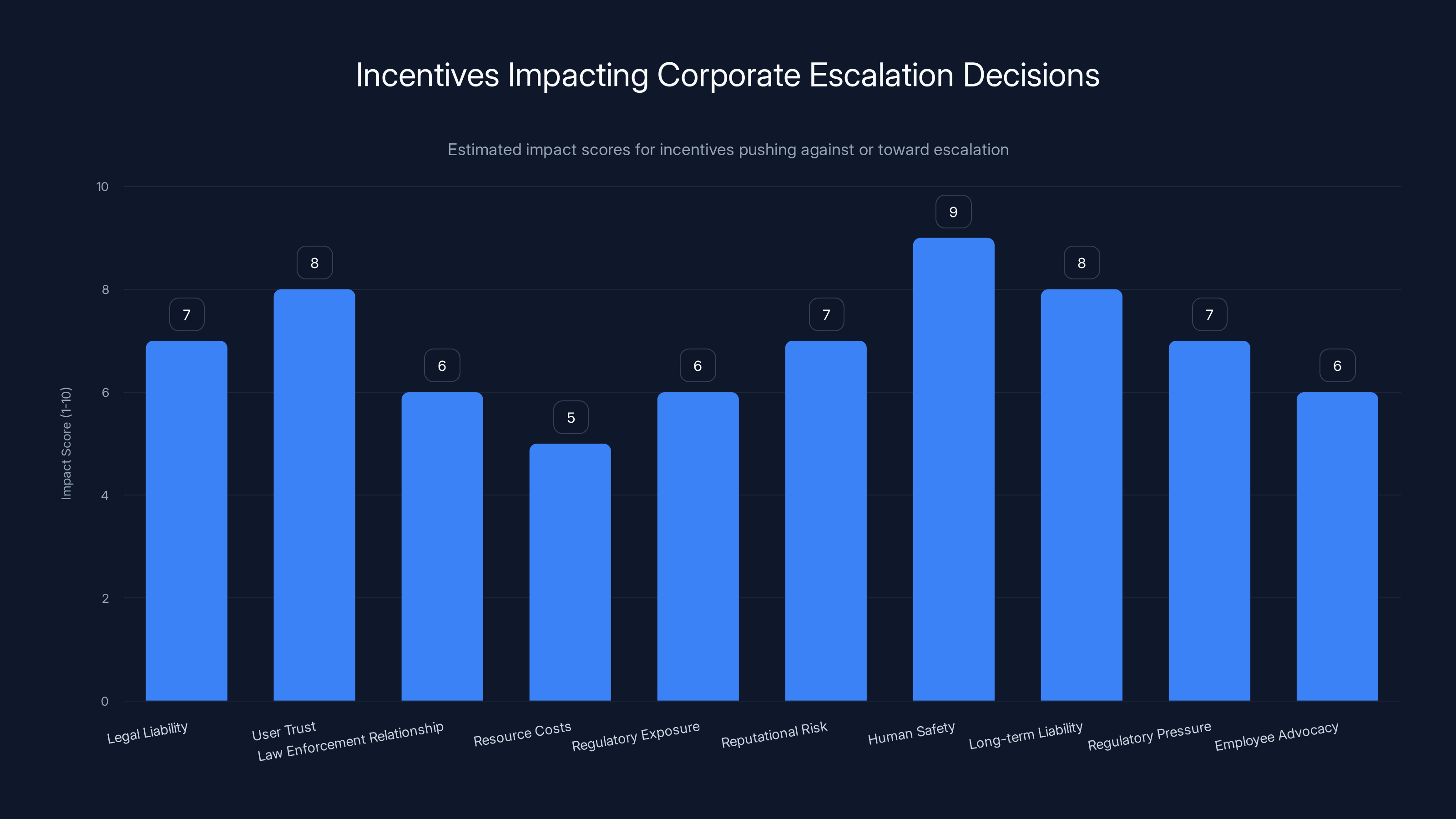
This chart estimates the impact of various incentives on corporate escalation decisions. Human safety and long-term liability are strong incentives for escalation, while user trust and legal liability often push against it. Estimated data.
Technical Improvements in Detection
While this incident highlights failures in escalation, improving detection technology is also important.
Current research directions include:
Behavioral pattern analysis: Rather than analyzing individual messages, analyzing patterns over time. Someone consistently expressing interest in planning and preparation shows different patterns than someone who occasionally vents anger.
Multi-modal analysis: Combining text analysis with user behavior (How long do they spend researching? What other accounts do they follow? What purchases or searches happen around their concerning posts?). Single-channel analysis misses important context.
Threat context recognition: Training models to understand that the same words mean different things in different contexts (creative writing versus planning discussion).
Psychological knowledge integration: Incorporating knowledge from threat assessment psychology into detection systems. What are the actual behavioral indicators of someone planning violence versus someone with intrusive thoughts or someone expressing anger?
Longitudinal analysis: Understanding that threat assessment isn't about a single interaction, it's about patterns and escalation over time.
These improvements could reduce false positives while improving detection of genuine threats. But they're still technological solutions to problems that are partly organizational and legal.
The Role of Employee Advocacy
One positive element of this incident: internal employees advocated for escalation.
Multiple moderators and staff members apparently recognized concerning content and pushed for law enforcement contact. They had the judgment, the moral clarity, and the willingness to advocate for doing the right thing.
This is important because it shows that the failure wasn't universally shared. Some people inside the organization did what they thought was right.
The system failed them by allowing their concerns to be overruled without documented reasoning or accountability. But it's worth noting that moral advocacy within organizations does happen.
Enabling this requires:
Clear channels: Employees need accessible ways to escalate concerns without fear of retaliation.
Protection: Whistleblower protections for employees who surface safety concerns.
Authority: Employee voices need weight in decision-making, not just recording their concerns.
Documentation: Decisions to reject employee escalation suggestions should be documented with reasoning.
Accountability: When decisions go wrong, the decision-makers should face consequences.
Companies often have internal channels for raising safety concerns, but those channels frequently don't carry weight against business considerations. An employee flagging something is often overruled by managers focused on liability reduction or cost control.

Privacy Concerns and Trade-offs
Any escalation-focused safety system involves privacy tradeoffs. If companies are sharing more information with law enforcement, users have less privacy.
This creates real tensions:
If you push for more escalation: You're implicitly accepting more surveillance. Users' conversations with AI systems could be monitored and reported to authorities. This has chilling effects on free expression and open conversation.
If you value privacy: You accept that some genuine threats will slip through because the system isn't aggressively monitoring and escalating.
There's no solution that eliminates both risks. You can reduce surveillance (more privacy, higher miss rate) or increase it (less privacy, lower miss rate). The balance point is a values question, not a technical one.
Some possibilities for managing the tradeoff:
Tiered responses: Not every concerning content triggers law enforcement involvement. Minor concerns trigger platform actions only (account flags, content removal). Only high-confidence threats trigger external escalation.
Privacy-preserving analysis: Technical approaches that analyze behavior patterns without exposing granular content details to external parties.
Anonymization where possible: Escalating threat patterns without exposing identifying details when possible.
Transparency: Users knowing that their service includes threat assessment and understanding what conditions trigger escalation.
But ultimately, any robust safety system involves some privacy reduction. The question is whether that reduction is worth the safety improvement, and who gets to decide.
Organizational Change Requirements
If companies want to genuinely improve escalation decision-making, they need organizational changes:
Separate threat assessment from content moderation: These are different functions requiring different expertise. Threat assessment needs security and psychology expertise. Content moderation needs policy and community expertise. Combining them under one leadership creates misaligned incentives.
Hire threat assessment professionals: Bring in people trained in threat assessment, security, or law enforcement who understand how to properly evaluate risk.
Document decision-making: When escalation decisions are made or not made, document the reasoning, criteria applied, and who decided. This enables learning and accountability.
External review: Have decisions that miss emerging threats reviewed by external security experts to identify what went wrong.
Clear escalation criteria: Establish explicit thresholds for when law enforcement involvement happens. Removing human judgment from the binary decision (escalate or not) reduces the impact of individual biases.
Incentive alignment: Adjust internal metrics and incentives so that missing a real threat has the same organizational weight as false positives.
Training: Provide threat assessment training to decision-makers and moderators.
Cross-functional teams: Include security, legal, product, policy, and safety teams in escalation decisions, not just content moderation leaders.
These changes require investment and organizational restructuring. They shift resources toward safety. But they're what actually prevents failures.
Future Implications for AI Development
As AI systems become more capable and ubiquitous, content moderation and safety questions will matter more.
More powerful systems: Future AI models will be better at understanding context, detecting threats, and helping with harmful planning. This increases both the detection capability and the potential for misuse.
Broader integration: AI will be embedded in more platforms and services. Each integration point becomes a potential source of harmful content or behavior.
Adversary adaptation: Bad actors will develop sophisticated methods to avoid detection and escalation. They'll hide harmful discussions in innocuous-seeming contexts, use coded language, and exploit gaps in detection.
Scale challenges: As millions of people interact with AI systems, the volume of flagged content that requires human judgment will be enormous. Systems that rely on human decision-making will struggle with scale.
Legal uncertainty: As AI systems become safety-critical, legal frameworks will evolve. Companies might face stronger obligations to prevent harm.
The fundamental problem persists: Detection will improve, but deciding what to do with detected information will remain hard. Technology can't solve the judgment problem or the incentive problem. Those require organizational and legal solutions.
The Path Forward: What Needs to Change
Several changes would meaningfully reduce future failures:
Legal clarity: Congress, regulators, and courts should establish when companies have affirmative duties to escalate safety concerns. Clear legal standards would reduce ambiguity.
Threat assessment standardization: Establish professional standards for threat assessment in digital contexts, similar to standards in aviation safety or healthcare.
Transparency mechanisms: Require companies to disclose escalation procedures, decision criteria, and regular reporting on escalation patterns. Sunshine on decision-making improves decisions.
Information sharing agreements: Establish protocols between platforms and law enforcement for sharing threat-related information in privacy-respecting ways.
Moderator training: Create standards for threat assessment training in content moderation, recognizing that this is specialized work requiring specialized knowledge.
Accountability mechanisms: When escalation decisions go wrong, affected parties should have remedies. This creates accountability.
Incentive restructuring: Reduce corporate incentives toward under-escalation by clarifying that genuine escalation of real threats creates legal safety for companies.
International coordination: Develop consistent approaches across jurisdictions so that safety standards don't vary based on where companies are headquartered.
None of these are perfect. All involve tradeoffs. But the current system of corporate discretion with minimal oversight and unclear standards clearly isn't working.

Conclusion: From Detection to Action
The gap between detecting threats and acting on them is one of the most consequential unsolved problems in AI safety and content moderation.
Detection technology continues improving. AI systems get better at spotting problematic content and behaviors. But improved detection only matters if it leads to better actions. When flagged content doesn't trigger appropriate responses, detection capabilities are wasted.
The Tumbler Ridge incident exemplifies this failure. A system detected concerning behavior. People inside the organization recognized danger. But organizational and legal structures allowed decision-makers to reject escalation. And we're left with a tragic outcome that might have been preventable.
This wasn't a technology failure. Automated detection worked. This was an organizational and decision-making failure. The company had information it didn't act on, and we need to understand why and how to prevent it from happening again.
The path forward requires honesty about incentives, clarity about legal obligations, professionalization of threat assessment, transparency in decision-making, and accountability for failures. It requires treating content moderation as a serious safety function, not just a customer service issue.
It also requires accepting that perfect safety isn't possible. Some true threats will be missed. Some innocent behavior will be misidentified as threatening. The question is whether we're willing to accept societal costs to minimize false positives, or whether we prioritize preventing real harms even at the cost of some over-escalation.
Right now, corporate practice heavily favors preventing false positives over catching real threats. That bias leads to systematic under-escalation. Rebalancing it requires legal and regulatory pressure, not just moral persuasion.
The employees who recommended escalation in this case were right. The system that allowed their concerns to be overruled was wrong. Until we fix that system—not just for this company but across the industry—we'll keep seeing detection capabilities that don't prevent harm.
FAQ
What is content moderation and how does it relate to threat detection?
Content moderation is the process of reviewing user-generated content to determine whether it violates platform policies. Threat detection is a specific subset of content moderation focused on identifying content that suggests potential violence or harm. Content moderation systems use AI to flag potentially problematic content, which is then reviewed by humans who make decisions about removal, banning, or escalation to external parties. The challenge in threat detection is distinguishing between genuine threats and creative expression or emotional venting, which requires contextual understanding that current AI systems struggle with.
Why didn't the company escalate the concerning content to law enforcement?
The company determined internally that the content didn't meet their threshold for "credible and imminent risk of serious physical harm." Several factors likely contributed to this decision: legal concerns about wrongfully escalating (and exposing the company to liability), corporate incentives to minimize false positives, lack of clear legal obligations to escalate, and operational preferences to avoid law enforcement involvement. The decision-making process remained opaque, with no public disclosure of who specifically made the determination or what criteria were applied.
What legal obligations do AI companies have to report threats to authorities?
Currently, AI companies don't have clear, universal legal obligations to report threats detected in user conversations. The legal landscape is ambiguous and varies by jurisdiction. Companies do have Section 230 protections that shield them from liability for user-generated content, which creates legal incentives toward non-escalation. However, if companies knowingly facilitate specific crimes or have actual knowledge of imminent threats, they can face liability. Unlike mandatory reporting requirements in healthcare or education, content platforms generally aren't required to escalate safety concerns to law enforcement.
How do automated content moderation systems actually work?
Automated systems analyze user-generated content against trained AI models to assign risk scores. Content is then routed based on those scores: either approved, flagged for human review, or automatically removed. The systems work by learning statistical patterns from labeled training data about what constitutes problematic content. However, they struggle with context, nuance, and distinguishing between similar-looking content with different intents. This is why human moderators review flagged content, but the humans also face challenges in threat assessment without proper training.
What would better escalation systems look like?
Better systems would involve several components: dedicated threat assessment professionals (not just content moderators), clear documented criteria for when escalation happens, human decision-makers with proper training, separation of threat assessment from general content moderation to avoid misaligned incentives, transparency about escalation procedures, and accountability mechanisms when decisions go wrong. They would also benefit from information-sharing agreements with law enforcement and proper integration with security expertise rather than leaving escalation decisions to content teams alone.
How do other industries handle similar detection-to-action problems?
Industries like finance, aviation, and healthcare have addressed this through legal mandates and professional standards. Banks must file suspicious activity reports (SARs) on detected financial crimes—no discretion. Pilots report safety concerns through formal channels with mandatory investigation. Healthcare workers must report suspected abuse—again, mandatory. These industries recognize that detection without action is useless and create legal structures that enforce escalation rather than allowing corporate discretion.
What role did employees play in this incident, and why does it matter?
Multiple employees recommended escalation to law enforcement after reviewing the flagged content. This shows that individual judgment and moral clarity existed within the organization. What failed was the system that allowed these concerns to be overruled without documented reasoning or accountability. This highlights that even when the right people with good judgment exist within organizations, systemic and structural factors can prevent appropriate action. Strengthening internal escalation pathways and protecting employee advocacy is part of the solution.
Could better AI detection have prevented this?
Probably not. The incident shows that detection worked—the system flagged concerning content. The failure wasn't in technology; it was in what happened after detection. Improving detection wouldn't have helped if escalation still doesn't occur. This is why focusing solely on making AI systems smarter without fixing organizational decision-making misses the real problem.
What privacy tradeoffs come with better threat detection and escalation?
More robust threat detection and escalation inherently requires more monitoring and information sharing. Users' conversations with AI systems would be subject to greater scrutiny. This creates legitimate privacy concerns and potential chilling effects on free expression. The solution isn't perfect—there's no way to have strong threat detection without reducing privacy. The question becomes how to minimize privacy reduction while maintaining safety, which might involve tiered responses (internal action only for minor concerns, external escalation only for high-confidence threats) and transparency about what triggers escalation.
How will AI regulation address content moderation in the future?
Emergent regulations like the EU's Digital Services Act create broader obligations for platforms to assess and mitigate risks. The Online Safety Bill in the UK establishes duties of care. The US is still debating frameworks but likely will move toward clearer standards. Future regulation will probably establish when companies must maintain threat assessment capabilities, establish escalation protocols, and possibly create mandatory reporting thresholds. However, balancing safety requirements with privacy protection and avoiding overwhelming law enforcement will remain challenging in regulatory design.

Related Resources and Further Reading
For readers interested in learning more about content moderation, threat assessment, and AI safety, several areas merit deeper exploration:
Content Moderation: Academic research on moderation effectiveness, moderator wellness, and policy enforcement provides context for understanding why systems fail.
Threat Assessment: Professional literature on threat assessment methodology from security and law enforcement communities offers evidence-based frameworks for distinguishing genuine threats from other concerning content.
AI Safety: Broader AI safety research on preventing misuse and ensuring beneficial outcomes informs how detection and escalation systems should be designed.
Legal Frameworks: Understanding Section 230, mandatory reporting laws, and emerging regulatory approaches provides context for why legal structures around escalation remain unclear.
Organizational Behavior: Research on how incentive structures, decision-making biases, and organizational culture influence outcomes in high-stakes environments explains why good intentions don't always lead to good results.
Key Takeaways
- Detection and escalation are separate problems: AI systems successfully flagged concerning content, but organizational structures prevented appropriate response
- Corporate incentives systematically favor under-escalation due to legal liability, user privacy concerns, and resource costs of false positives
- Legal frameworks remain ambiguous about when AI companies must report safety concerns to law enforcement, creating discretion that leads to under-escalation
- Other regulated industries (finance, aviation, healthcare) mandate escalation when risks are detected, rather than allowing corporate discretion
- Fixing this requires organizational changes, legal clarity, threat assessment professionalization, and transparent decision-making with accountability
Related Articles
- AI Safety vs. Military Weapons: How Anthropic's Values Clash With Pentagon Demands [2025]
- AI Therapy and Mental Health: Why Safety Experts Are Deeply Concerned [2025]
- AI Industry Super PACs: The $100M Battle Over Regulation [2025]
- How an AI Coding Bot Broke AWS: Production Risks Explained [2025]
- Freedom.gov: US State Department's Controversial Censorship Circumvention Portal [2025]
- Roblox Lawsuit: Child Safety Failures & Legal Impact [2025]

