![AI Agents in Production: What 1 Trillion Tokens Reveals [2025]](https://tryrunable.com/blog/ai-agents-in-production-what-1-trillion-tokens-reveals-2025/image-1-1771673761517.jpg)
AI Agents in Production: What 1 Trillion Tokens Reveals [2025]
If you're reading another AI agent blog post that tells you whether they're "ready" or "overhyped," stop. The debate is over. The data is in.
Someone's processing the signal, and it's not a venture capitalist or a consultant making predictions. It's Chris Clark, Co-Founder and COO of Open Router, sitting at one of the most unique vantage points in AI infrastructure. His company runs the world's largest AI gateway, routing trillions of tokens per week across 70+ model providers, dozens of cloud environments, and every geography on Earth.
He's not hearing what companies claim they're doing. He's seeing what they're actually doing. At scale. Every single day.
The data tells a story so clear that it changes how you should think about AI agents, their real adoption curve, production readiness, and where the actual investment and innovation are happening in 2025.
TL; DR
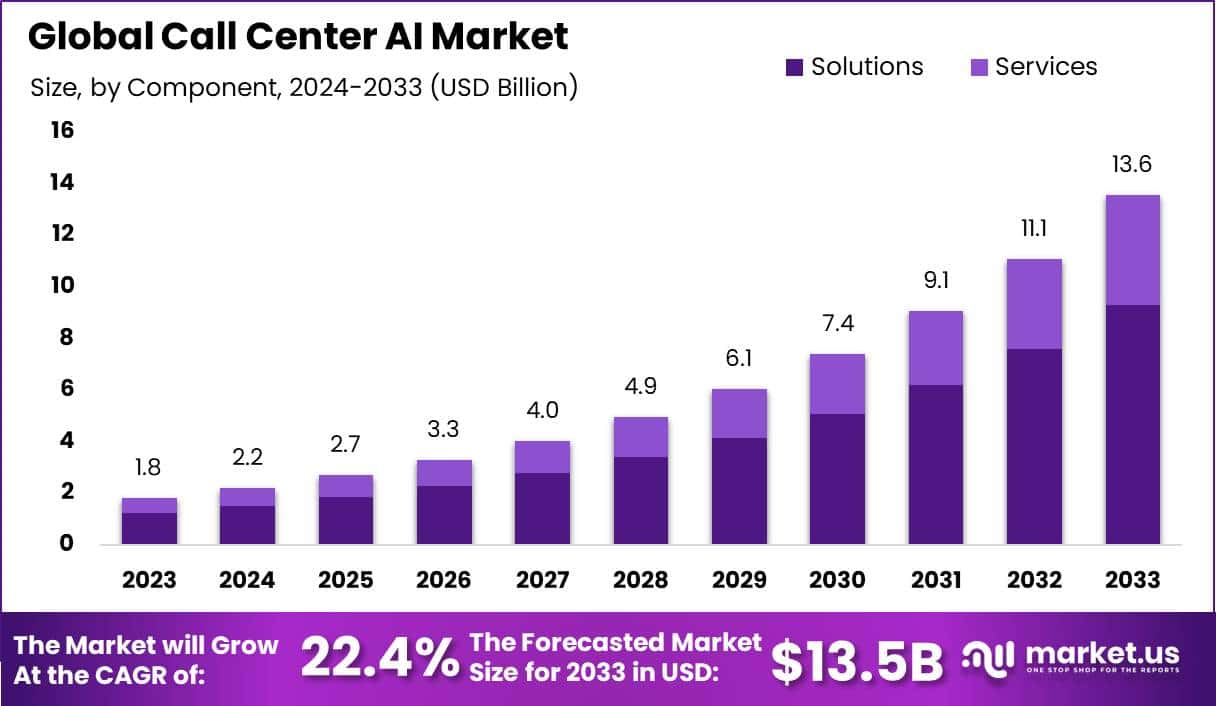
- Tool call rates exploded: From under 5% to over 25% in 12 months, signaling agents moving from experimental to operational
- The July shift: Customer behavior changed dramatically when companies started negotiating SLAs instead of discussing features, indicating genuine production dependency
- Reasoning tokens dominate: Internal reasoning tokens now represent 50% of all output tokens, up from zero 13 months ago
- Hybrid architecture wins: Frontier models for planning, smaller open-weight models for execution is becoming the standard production pattern
- Cost structure matters: The actual economics of production agents reveals why Chinese open-weight models are gaining unexpected market share in U.S. companies
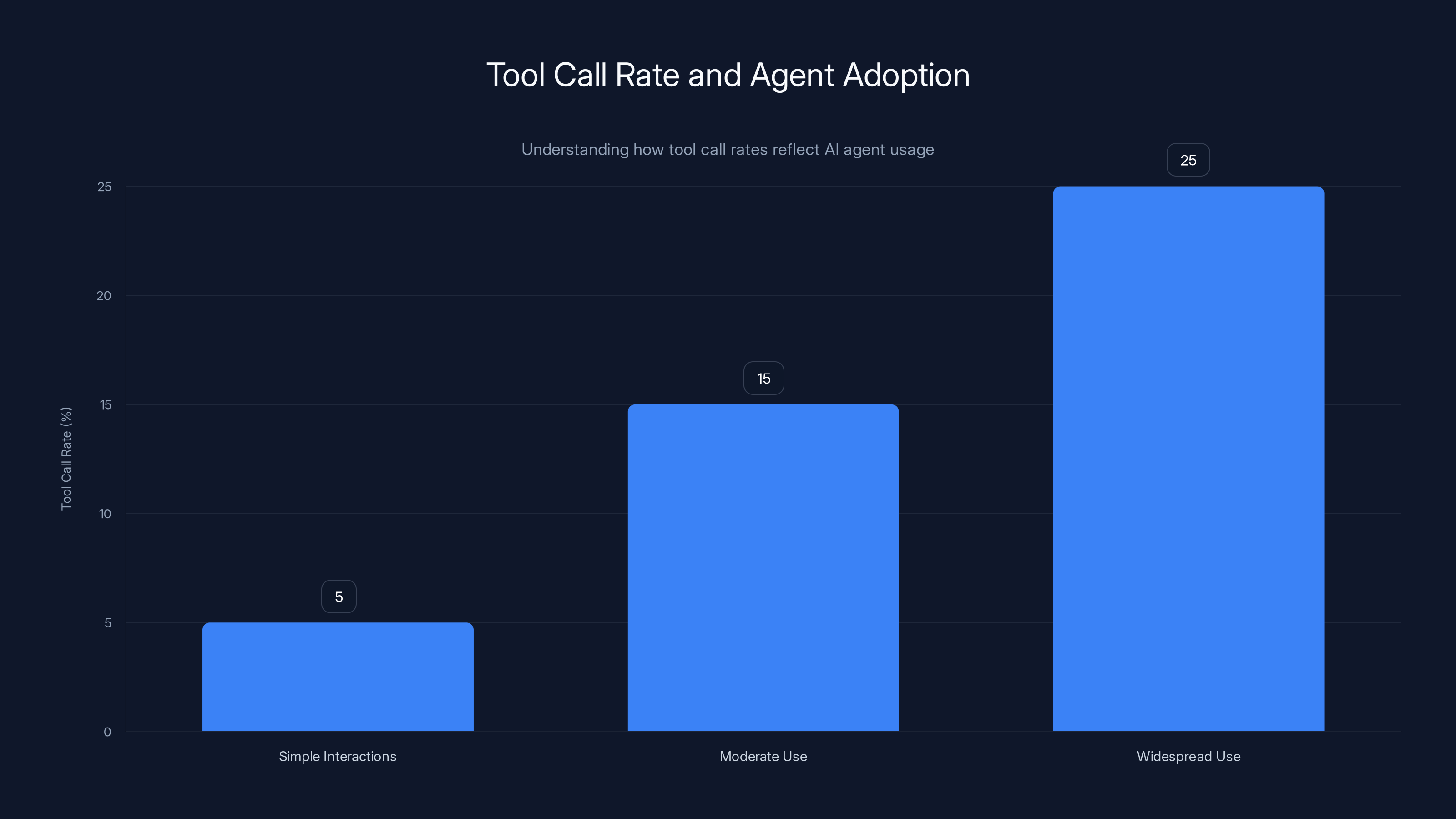
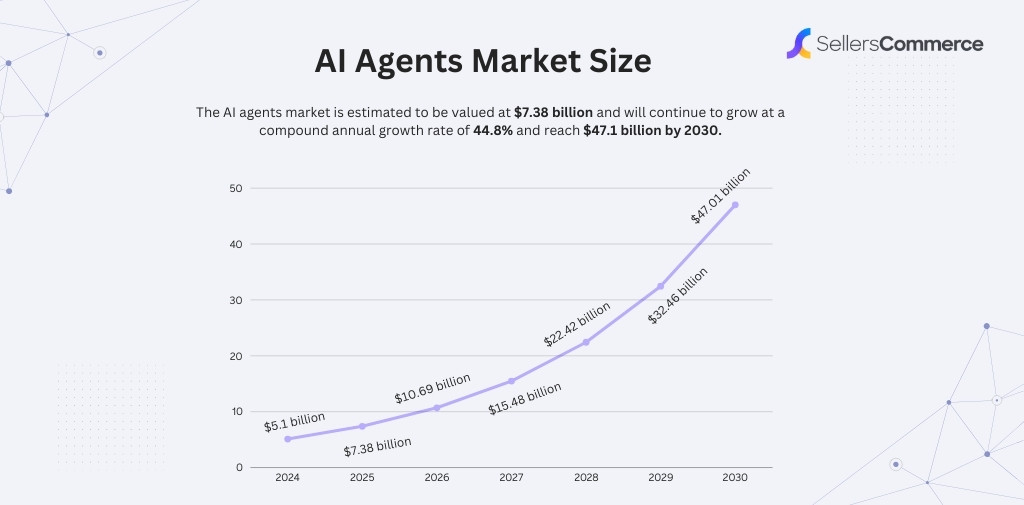
A tool call rate above 25% indicates widespread use of agentic patterns, showing a high level of AI agent adoption.
What Open Router Actually Sees: Beyond the Hype
Most AI industry analysis comes from surveys, interviews, or educated guesses. Open Router has something better: telemetry from actual production workloads.
Think about what this means. When a company deploys an AI agent that calls your database, sends emails, or processes transactions, Open Router's infrastructure is routing those requests. When a model needs to execute a tool call, that decision is captured in their data. When a company decides to optimize costs by switching models, that behavioral shift shows up in their logs.
This isn't theoretical. This is what 1 trillion tokens per day looks like in practice.
The reason this matters is simple: there's a massive gap between what companies claim and what they're actually doing. In survey-based analysis, everyone's an adopter. In real infrastructure data, you see the truth. You see which features are actually used. You see which patterns are mainstream versus niche. You see the inflection points when something stops being interesting and starts being critical.
Open Router's vantage point reveals something that casual observers miss: the adoption curve for AI agents isn't linear. It's not smooth. It has clear inflection points, and those inflection points correspond to specific moments when agents stopped being experiments and started being infrastructure.
The company sees this across multiple signal types: quantitative behavioral metrics, qualitative customer interactions, usage pattern shifts, and architectural choices. When you triangulate all four, the picture becomes crystal clear.
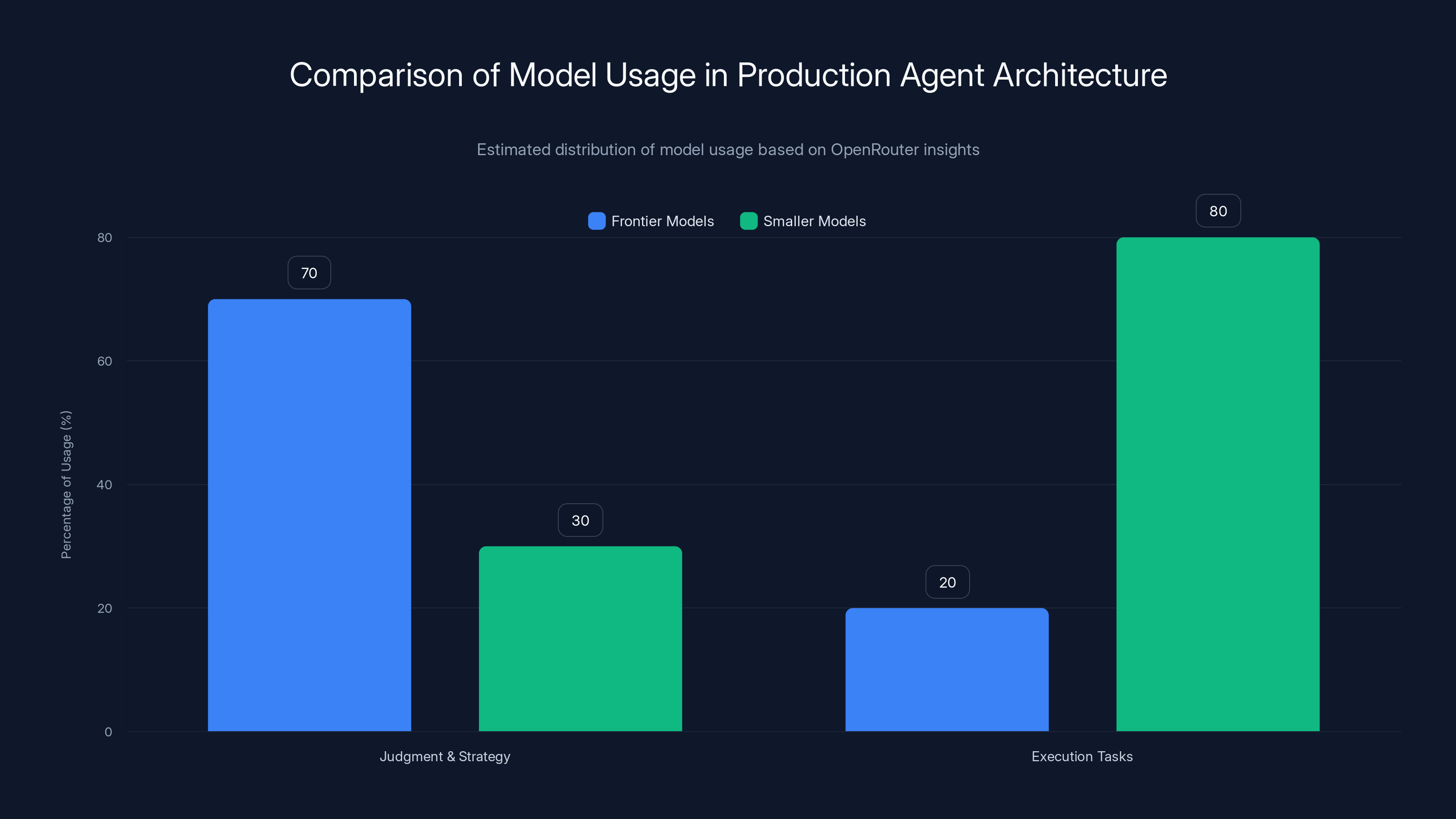
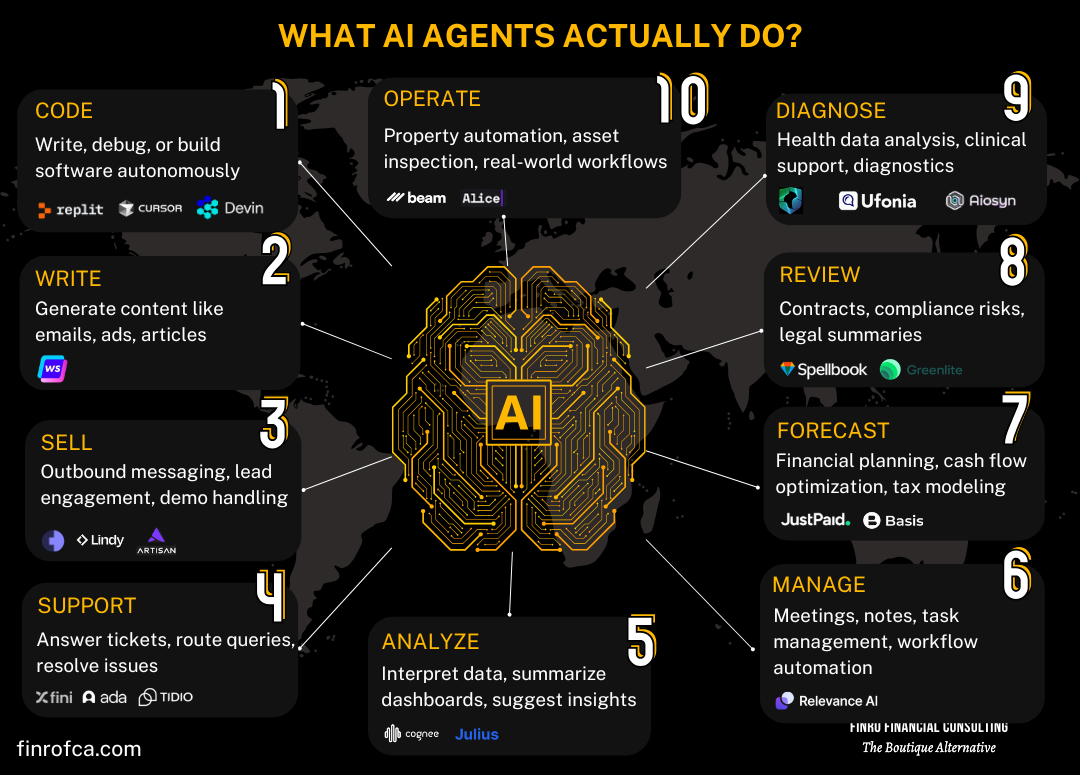
Frontier models are predominantly used for judgment and strategy, while smaller models excel in execution tasks. Estimated data based on industry trends.
The Tool Call Explosion: From 5% to 25% in 12 Months
Understanding this metric requires understanding what a tool call actually is.
An LLM, at its core, does one thing: it takes text as input and outputs text. That's the entire capability. It cannot directly call a database. It cannot execute a payment. It cannot read a file system. It cannot browse the internet.
What it can do is output structured text that says: "Please call this function for me." That's a tool call. It's the model saying, "I've decided the right next step is to query the user database. Here's what I want you to do."
Then, the software framework around the model executes that call. It runs the function. It captures the result. It feeds that result back to the model. The model reads the result and decides what to do next. Then it either requests another tool call or produces a final answer to the user.
When you loop this repeatedly, that's an agent. It's not magic. It's a simple pattern: LLM outputs text → software executes → result loops back → repeat.
Now, back to the metric. Open Router publishes detailed data on what percentage of API requests across major models result in a tool call request. For Claude, which is widely representative of global usage trends, that number was under 5% about twelve months ago. Today, it's well north of 25%.
That's not a feature uptick. That's not a niche use case exploding. That's a fivefold increase in the prevalence of a usage pattern in just one year.
To put this in perspective, imagine if web framework usage went from 5% of internet traffic to 25% in twelve months. That would signal a fundamental shift in how web applications are built. That's what this metric represents for AI.
For specialized agentic models like Minimax M2, the numbers are even more dramatic. Some of these models see tool call rates above 80%. These aren't general-purpose models being used in diverse ways. These are models purpose-built for agentic loops, and companies are using them exactly as designed.
What makes this even more significant is the consistency. This isn't a spike in one company or one vertical. This is a median trend across hundreds of companies, dozens of industries, and multiple geographies. It's broad-based adoption, not concentrated hype.
The July Inflection Point: When Agents Became Critical
Quantitative metrics tell part of the story. Sometimes the qualitative signals are even more powerful.
Around Mid-July 2024, Open Router's sales and business development team noticed something unusual. Customers started asking a specific question they'd never asked before.
Not "What's the pricing?" Not "How fast is it?" Not "What models do you support?"
They asked: "What's your SLA?"
SLAs—Service Level Agreements—are what you negotiate when something going down has real business consequences. Nobody cares about SLAs for a prototype or a demo. SLAs matter when the system being down means you lose revenue, disappoint customers, or violate commitments.
In March 2024, agents were still in the experimentation phase across most companies. Sales conversations were transactional. Customers signed typical SaaS contracts, discussed features, evaluated pricing. It was the normal software sales cadence.
Then something shifted.
By July, customer conversations fundamentally changed. Companies weren't asking about features anymore. They were asking operational questions: "What's your uptime percentage?" "How do you handle failover?" "How do we think about your uptime relative to the model provider's uptime?" "What happens if you go down at 3 AM on a Sunday?"
These are the questions you ask when you've moved an agent from a sandbox to production. When it's handling real transactions. When customers depend on it. When it's integrated into a critical workflow.
The shift was sharp enough that the Open Router team noticed it without specifically tracking for it. It emerged naturally from conversations.
This is a crucial inflection point that most observers completely miss. Tool call rates increasing gradually could be explained by feature awareness and experimentation. But when customer conversations shift from "feature evaluation" to "operational readiness," that signals a different kind of adoption. That signals production dependency.
What happened between March and July? It wasn't a single product launch or breakthrough. It was accumulation. Companies had been experimenting with agents. Some of those experiments worked. Some worked so well that they decided to move them to production. Once agents were running real business logic, their operational characteristics became critical.
This threshold crossing—from experiment to production—is what drove the SLA questions.
It also explains why tool call rates continued climbing after July. Once companies made the decision that agents were operationally critical, they invested more heavily in agentic workflows. They built more agents. They refined existing ones. They optimized for cost and reliability. That investment is reflected in the tool call data.
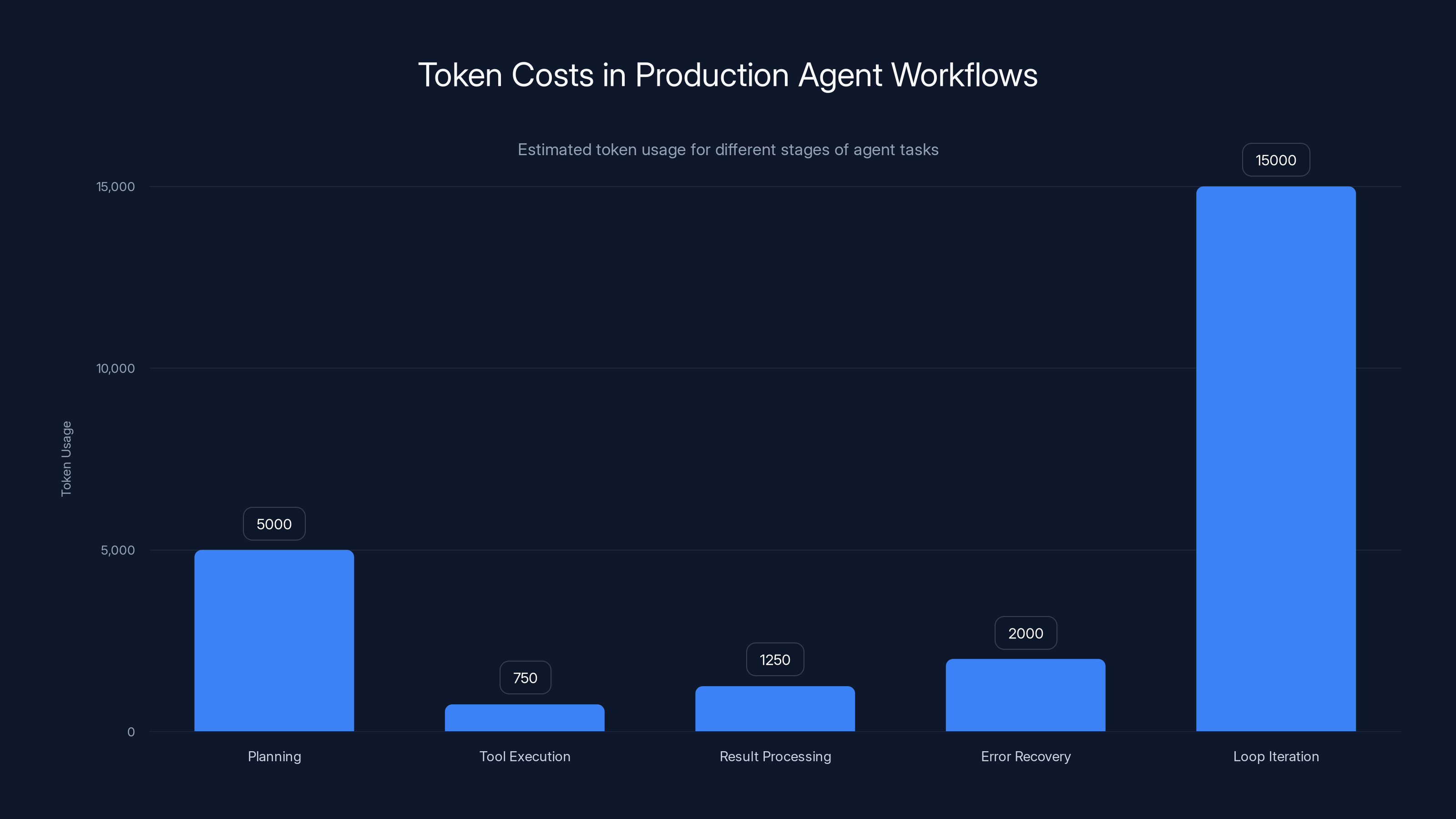
Estimated data shows planning and loop iterations are the most token-intensive stages in agent workflows, highlighting the complexity and cost of these processes.
Reasoning Tokens: From Zero to 50% of Output in 13 Months
There's a category of capabilities that didn't exist in mainstream AI a little over a year ago. Reasoning models—systems that explicitly show their work before producing an answer—simply weren't available.
In early 2025, that changed. Open AI released O1, later followed by O3. These models introduced a fundamentally different approach: they allocate compute to internal reasoning, showing chain-of-thought work before producing a final answer. The reasoning process is expensive and slow, but it produces more reliable outputs on complex problems.
When these models first launched, they were expensive, slow, and novel. Most people thought they'd be a niche tool for specialized use cases. Maybe for debugging complex code or working through theoretical problems.
But the data tells a different story.
Today, roughly 50% of the output tokens that Open Router processes are internal reasoning tokens. These are the tokens generated during the thinking phase, before the model produces its actual answer. Half of all tokens.
This is staggering adoption for a capability that literally didn't exist thirteen months ago.
What does this reveal about production agent behavior?
Companies are using reasoning for planning. When an agent needs to decide which tools to call, in what order, and with what parameters, reasoning tokens are helping that decision-making process. The model thinks through the problem, shows its work, and then executes confidently.
This makes sense for production systems. If an agent is going to make a database modification, delete a user, or trigger a payment, you want that decision to come from a model that's explicitly reasoned through the implications. Reasoning tokens provide that capability.
Moreover, reasoning tokens are being used for error recovery. When an agent encounters an unexpected result, reasoning tokens help the model diagnose what went wrong and determine the right corrective action. This is critical for reliability in production.
The 50% figure also reflects a strategic choice that companies are making: spend more compute on thinking to reduce errors, rather than spend less compute and accept higher failure rates. In production environments, that's the right trade-off.
The Production Agent Architecture: What Actually Works
Here's where the data gets actionable.
Based on what Open Router sees at scale, a clear architectural pattern has emerged for production agents. This isn't theoretical best practice—it's what companies are actually building and deploying.
Step One: Frontier Models for Planning
The first layer uses the best models available from major labs. Claude Sonnet from Anthropic, GPT-4o from Open AI, Gemini from Google. These models handle the high-level reasoning, decision-making, and judgment calls.
When an agent needs to decide which customers to reach out to, what tone to use, whether to escalate a support request, or how to prioritize a workflow, a frontier model handles it. These models are expensive—significantly more expensive than smaller alternatives—but they're trusted to make judgments that matter.
The crucial insight is that companies aren't being forced to use frontier models for everything. They're choosing to use them specifically for the parts that matter most: judgment, strategy, and complex decision-making.
Step Two: Smaller Models for Execution
Once the plan exists—"reach out to these 50 customers with this message"—the actual execution happens with a different model. And here's where things get interesting.
Companies are increasingly routing execution to smaller, specialized, open-weight models. Particularly, models from Chinese labs like the Qwen family.
Why? These models aren't the smartest in raw capability. They won't win benchmarks on general knowledge or reasoning. But they're extremely accurate at structured tool use. They follow instructions precisely. They reliably format outputs correctly. They call the right functions with the right parameters.
For repetitive, well-defined tasks—"send this email," "update this database record," "generate this report"—they're more than sufficient. And they're a fraction of the cost.
Step Three: Continuous Optimization
As companies get comfortable with an agentic workflow, they optimize. This "downclutching" process is systematic.
They start with a frontier model for everything. It works, but it's expensive. Then they identify which specific tool calls are most frequent and least dependent on reasoning. They test using a smaller model just for those calls. If results are good, they keep it. They identify the next most-optimize-able step and repeat.
Over time, the architecture evolves. Maybe 70% of the tokens go to the small model, 30% to the frontier model. The frontier model handles edge cases, complex decisions, and anything that requires judgment. The small model handles everything routine.
This iterative optimization is visible in the data. Companies don't jump to this architecture immediately. They arrive at it through experimentation and cost pressure.
Why Chinese Open-Weight Models Are Winning
Here's what surprised many people: Chinese open-weight models have captured significant market share in agentic flows run by U.S. companies.
This isn't because U.S. companies have some special affinity for Chinese models. It's pure economics combined with architecture efficiency.
Models like Qwen are purpose-optimized for tool use. They were built in an environment where deploying agents at scale was already a priority. The training data, fine-tuning, and optimization all focused on reliability in agentic loops.
U.S. models, by contrast, were optimized for general capability and benchmark performance. Tool use was an afterthought. So when companies start building production agents, the Chinese models often outperform U.S. models on the specific dimension that matters: correct tool execution.
Add to that the cost advantage—open-weight models can be self-hosted or used cheaply at inference time—and you have a compelling value proposition.
This is reflected in the token data. Chinese open-weight models are disproportionately heavy in agentic workloads specifically, but much less prevalent in general-purpose LLM usage. The architecture of agents creates demand for their particular strengths.
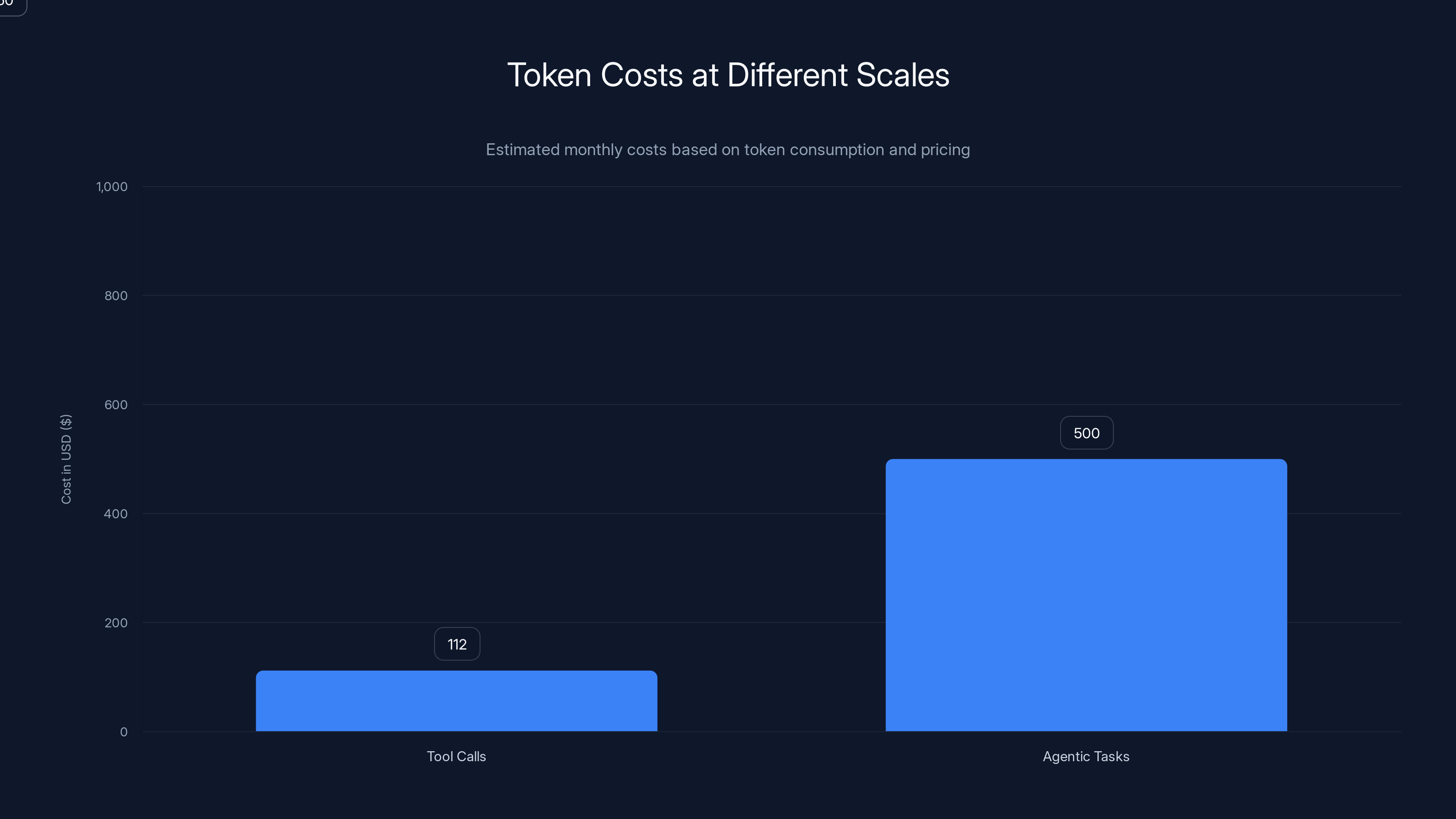
Estimated data shows that agentic tasks at scale can lead to significant monthly costs, highlighting the importance of optimizing token usage.
The Inference Quality Problem Nobody Discusses
Here's something counterintuitive that the data reveals but most discussions ignore.
When a model is only used for inference—generating an output based on an input—output quality is relatively straightforward to measure. You look at accuracy, latency, cost. Done.
But agents aren't pure inference. They're loops.
When an agent calls a tool, it gets a result. That result goes back into the model. The model reads it and decides what to do next. If the model misunderstood the result, or if the tool call itself was malformed, the agent can end up in a bad state.
This is the "inference quality" problem in agentic loops. It's not about how good the model is in isolation. It's about how good the model is at reading, understanding, and responding to tool results.
Some models are terrible at this. They misread tool outputs, forget context, or make bad decisions based on results. These models might benchmark well but fail consistently in production agents.
Other models excel at it. They carefully read each tool result, integrate it into their understanding, and make coherent next decisions. These models might be less flashy in benchmarks but are incredibly reliable in agents.
This quality dimension isn't captured in standard benchmarks. It requires building actual agents and measuring success over multi-step loops. But it's absolutely critical for production systems.
Open Router sees this play out in their data. Certain models have statistically higher success rates in agentic workflows despite not being the "best" models on standard benchmarks. Companies deploying production agents learn this and adjust their routing accordingly.
Cost Structure: The Economics of Production Agents
Production agents have a specific cost structure that differs significantly from regular inference.
With standard LLM usage, the cost model is relatively simple. You pay per token. Bigger models cost more. Longer contexts cost more. That's it.
With agents, cost has multiple dimensions.
Planning token cost: The frontier model handling planning is expensive. It might use 5,000 tokens to understand the task, reason through options, and decide on a plan.
Tool execution token cost: Each tool call might require 500-1,000 tokens from the execution model to properly format and call the tool.
Result processing cost: When the tool result comes back, it needs to be read and interpreted. That's another 500-2,000 tokens depending on result complexity.
Error recovery cost: If something goes wrong, the agent needs to diagnose and recover. That's additional tokens, possibly using the expensive frontier model.
Loop iteration cost: Multi-step agents might iterate 3-10 times for a single task. Each iteration incurs full costs across planning, execution, and result processing.
A single user request might consume 20,000-100,000 tokens across multiple models. For context, a simple API call might use 500 tokens.
This cost structure explains several observations:
First, why companies are using frontier models for planning but cheaper models for execution. The cost difference compounds across hundreds of thousands of tasks.
Second, why reasoning tokens—which are expensive—are being used despite their cost. If reasoning reduces error rates by 30%, it more than pays for itself in avoided re-iterations.
Third, why optimization and downclutching are so important. A 50% reduction in tokens per task is potentially a 50% reduction in operational cost. That's worth significant engineering effort.
Fourth, why agent design matters. A poorly designed agent that requires 15 loop iterations is far more expensive than a well-designed agent that completes in 3 iterations. Architecture is an economic question, not just a technical one.

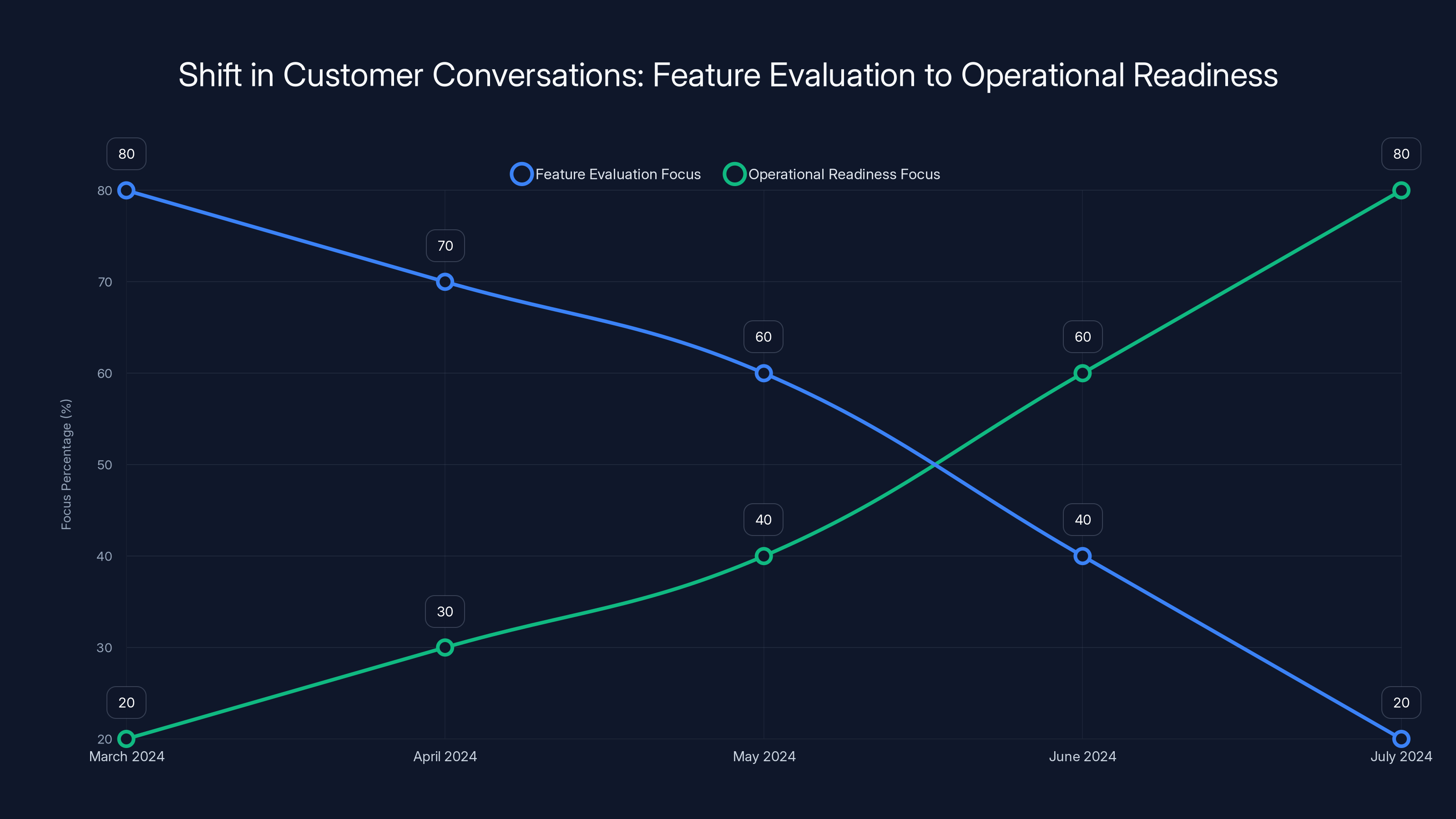
Estimated data shows a significant shift from feature evaluation to operational readiness in customer conversations by July 2024, indicating a move from experimentation to production use.
What the Data Reveals About Agent Reliability
One of the most practically useful insights from Open Router's vantage point is what reliability actually looks like in production agents.
Most discussions of LLM reliability focus on hallucinations or factual accuracy. But in agents, reliability means something different. It means:
- Deterministic tool calling: The agent consistently calls tools with correct parameters
- Stable loops: Multi-step workflows don't diverge or get stuck
- Error recovery: When something goes wrong, the agent recognizes it and recovers
- Cost predictability: Token consumption doesn't explode unexpectedly
The data shows that these reliability dimensions don't correlate perfectly with general model capability. A smaller model that's been fine-tuned for agents might be more reliable than a larger general-purpose model.
This has major implications for how companies select models. They're not just picking the best model. They're picking the model best suited to their specific use case.
For customer service agents, they're picking models with strong instruction-following. For data processing agents, they're picking models reliable at structured output. For planning agents, they're picking models with strong reasoning.
The sophistication here is worth noting. Companies aren't naive about model selection. They're matching models to specific functional requirements.
The Vertical Adoption Pattern: Where Agents Are Winning
Agent adoption isn't uniform across industries. The data reveals clear patterns.
Customer support and automation has the highest agent adoption. Helping customers, answering questions, routing issues—these are natural agentic workloads. Tool calls are queries to knowledge bases, CRM lookups, ticket creation. Companies in this space have moved agents from experimental to production at the highest rates.
Data processing and analytics shows strong agent adoption. Agents extract data from various sources, transform it, validate it, and load it into analytical systems. This is where automated ETL and data pipeline agents are most prevalent.
Business process automation is emerging as a major agent use case. Approvals, expense processing, vendor management, contract review—any workflow with clear steps and human hand-offs is getting an agentic layer.
Software development has moderate adoption. Agents helping with code generation, bug fixing, documentation—these exist but aren't dominant yet. The reason is likely that developers are selective. They want tools they deeply understand.
Healthcare and finance are notable for their absence. Both industries have regulatory constraints that slow agentic adoption. Agents making healthcare or financial decisions face liability questions that companies are still working through.
This vertical pattern is important because it reveals which use cases are genuinely winning versus which are hype. It's not about which vertical companies want agents in. It's about which verticals have found agent patterns that actually work better than existing approaches.
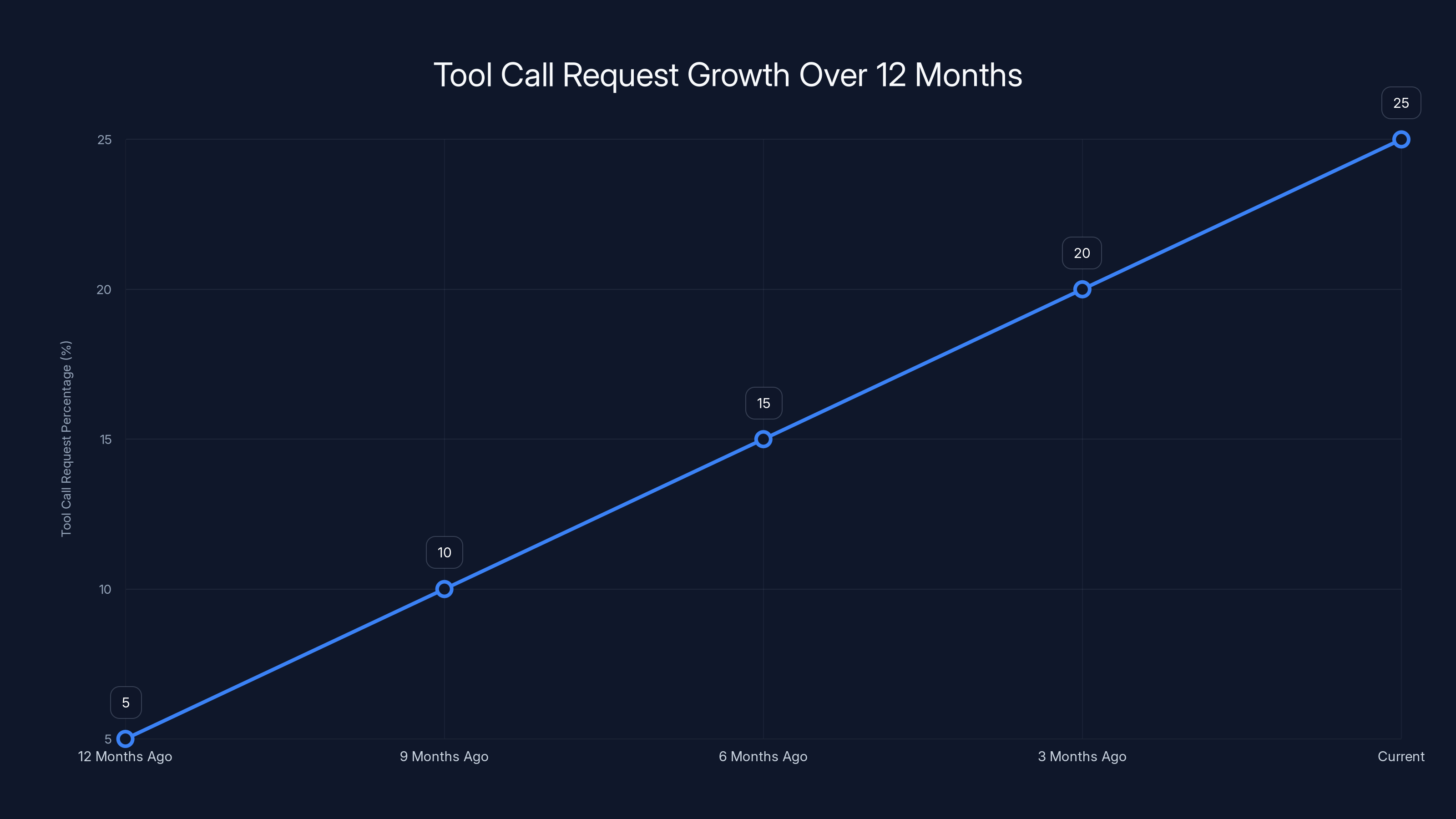
Tool call requests increased from 5% to over 25% in just 12 months, indicating a significant rise in the adoption of agentic behavior in production environments.
The Geographic Distribution: Where Agents Are Deployed
Open Router processes traffic globally, and the geographic distribution of agent adoption reveals something interesting.
U.S. companies dominate in agent experimentation and adoption. This makes sense—U.S. companies have better access to frontier models and are more willing to take adoption risk.
But there's a second wave emerging from Europe and Asia-Pacific. These regions are adopting different models and architectures. They're more likely to use open-weight models and to self-host or use regional providers. They're more cost-conscious and more willing to trade some performance for sovereignty and cost control.
China is a separate story. Chinese companies are ahead on agent adoption in many ways. They built agentic patterns earlier because they were optimizing for different constraints. The models available to them, the cost pressures they face, and their regulatory environment all pushed toward agentic architectures sooner.
This geographic variation is worth tracking because it suggests regional innovation is happening. U.S. trends toward frontier models, Europe toward open-source and self-hosting, China toward cost optimization and agentic efficiency.

The Inference Latency Tradeoff
One data point that often gets overlooked in agent discussions is latency.
Frontier models are slower than smaller models. Reasoning tokens make things slower still. Multi-step agents with loops mean you're waiting for sequential operations, not parallel inference.
A user submitting a request to an agent might wait 5-15 seconds for the full response, depending on how many loops are involved.
Is this acceptable? The data suggests yes, within reason.
For conversational agents where users expect processing time, 5-10 seconds is fine. For automated background agents running on your infrastructure, latency doesn't matter—you get results whenever they arrive.
But there are cases where latency is prohibitive. Real-time applications, user-facing synchronous operations, systems requiring sub-second responses. These aren't good use cases for complex agentic loops.
Companies are learning this through experience. They're being thoughtful about where agents add value versus where they create friction.
Token Volume Implications: Costs at Scale
Here's a sobering math exercise.
If Open Router is processing 1 trillion tokens per day, and tool call rates are 25%, that means roughly 250 billion tool-calling tokens daily across the entire infrastructure.
Each tool call might involve 2,000-5,000 tokens on average. That's hundreds of billions of tokens in tool-execution flows alone.
For a company deploying agents at significant scale, token costs can become substantial. A company running 1 million agentic tasks per day, each consuming 30,000 tokens on average, is dealing with 30 trillion tokens monthly.
At typical frontier model pricing (
For many use cases, this is economical. For others, it's prohibitive.
This is why the architectural pattern matters so much: push planning to frontier models, push execution to cheap models, minimize loop iterations. These optimizations aren't nice-to-have. They're essential for unit economics.

What's Actually Happening in Teams Building Agents
Based on what Open Router observes, here's the practical reality of how serious companies are building agents in 2025:
Phase 1: Feasibility Testing - Teams start with a frontier model, run multi-step workflows, verify that the basic pattern works. Cost doesn't matter; understanding does.
Phase 2: Refinement - Once the workflow is understood, teams refine the prompts, adjust the tool schema, optimize the loop structure. They're still using expensive models but they're learning what works.
Phase 3: Cost Optimization - After the workflow is solid, teams start swapping in cheaper models for execution steps. They measure quality, adjust accordingly. This is where downclutching happens.
Phase 4: Production Hardening - Once costs are reasonable, teams focus on reliability. Error handling, monitoring, fallback patterns, SLA management. This is where SLA questions start appearing in customer conversations.
Phase 5: Continuous Improvement - In steady state, teams monitor success rates, iterate on prompts, adjust model selections based on real performance. They're constantly optimizing within the constraints of their use case.
Companies don't all move through these phases at the same speed. But the data shows that the progression is consistent. Once a company decides agents are valuable, they follow this optimization arc.

The Future of Agent Architecture: Predictions Based on the Data
Where is this heading? The token data provides some clues.
Specialized models will proliferate: As agent adoption grows, model builders will create increasingly specialized models for specific agentic tasks. The era of one model doing everything is ending. The era of models optimized for specific architectures and workflows is beginning.
Reasoning will become the norm: The 50% reasoning token figure will likely stabilize or grow. Companies are learning that spending more tokens on thinking produces better results. This will drive investment in reasoning-optimized models.
Open-weight models will capture more market share: The downclutching pattern rewards open-weight models. As more companies move execution to cheaper models, open-weight alternatives will gain share relative to proprietary frontier models.
Multi-model orchestration becomes critical: Smart routing—choosing the right model for each part of an agent—becomes a core competency. Companies will use specialized tools to manage which models handle which steps.
Regulatory clarity will unlock new verticals: Healthcare, finance, and other regulated industries are waiting for legal clarity on agent liability. Once clarity emerges, these verticals will see rapid agent adoption.
Agent monitoring and observability become premium services: As agents become critical infrastructure, tools for monitoring agent behavior, understanding failures, and debugging multi-step workflows become increasingly valuable. This is an emerging market.
The Real Inflection Point Ahead
The data from 1 trillion tokens daily shows that AI agents have crossed from experimental to operational. Tool call rates, SLA negotiations, and reasoning token adoption all confirm this.
But the real inflection point hasn't arrived yet.
It arrives when agentic patterns become the default, not the exception. When new applications are designed with agents in mind from the start, not bolted on afterward. When the talent market shifts to reward agentic architecture expertise. When investment capital flows explicitly toward agent infrastructure and applications.
All of these are beginning, but none are complete.
The companies tracking the Open Router data—and understanding what 1 trillion tokens truly reveals—have a head start. They know agents are real. They know what works and what doesn't. They know the economics and the architectural patterns.
The rest of the market is still debating whether agents are ready. The data says they are. The only question is whether you'll build for a world where agents are central, or whether you'll be retrofitting when everyone else has moved on.

FAQ
What are AI agents and how are they different from regular LLM applications?
AI agents are systems where language models operate in loops, repeatedly calling external tools or functions and processing their results. Unlike regular LLM applications where the model generates a response and stops, agents continue iterating: they call a tool, receive a result, analyze it, decide on the next action, and repeat. This loop-based architecture enables agents to accomplish complex multi-step tasks like automating business processes, managing data workflows, or handling customer support scenarios that would require human intervention in traditional systems.
How does the tool call rate metric measure agent adoption?
The tool call rate represents the percentage of API requests where the language model explicitly requests to call an external tool or function. A rate below 5% indicates tools are rarely being used and applications are simple single-turn interactions. Rates above 25% indicate widespread use of agentic patterns where models are regularly deciding which functions to call, making decisions based on results, and iterating through multi-step processes. This metric directly correlates with production deployment because tool calling is the technical mechanism that enables agents to function.
Why are companies using multiple models in their agent architectures?
Companies use a hybrid approach because different models have different strengths and cost profiles. Frontier models like Claude Sonnet and GPT-4o excel at reasoning, planning, and judgment but are expensive. Smaller, open-weight models are fast and cheap but less sophisticated. By routing high-level planning and decisions to frontier models and routine execution tasks to smaller models, companies can maintain quality while reducing costs by 70-80%. This "downclutching" approach leverages each model's strengths where they matter most.
What is the significance of reasoning tokens becoming 50% of output?
Reasoning tokens represent the model's internal thinking process—its chain-of-thought before producing a final answer. When these tokens account for 50% of all output, it means companies are investing substantial compute in having models think through problems more carefully before deciding what to do. This is particularly important in agents where incorrect decisions propagate through multi-step loops. The high usage indicates that for production systems, the added cost and latency of reasoning is worth the improved reliability and decision quality.
How do Chinese open-weight models achieve success in agentic workflows despite being less capable overall?
Chinese models like Qwen were built in an environment where agentic deployment was already a priority, so they were optimized specifically for reliable tool use and structured output generation. While less capable at general reasoning or knowledge tasks, they excel at following precise instructions and formatting tool calls correctly, which is exactly what execution-layer agents need. Combined with lower costs from being open-weight, they provide superior value for the execution portion of hybrid architectures even though they wouldn't be chosen for planning or reasoning tasks.
What is the July 2024 inflection point and why does it matter for understanding agent adoption?
In July 2024, customer conversations with Open Router shifted dramatically from discussing features and pricing to negotiating Service Level Agreements (SLAs). This behavioral change signals that companies had moved agents from experimental projects to production systems where downtime has real business consequences. This inflection point is more meaningful than survey data because it reflects actual decision-making—companies only negotiate SLAs when they depend on a system being reliable, indicating genuine commitment to agents rather than continued experimentation.
How does agent architecture affect total cost of ownership?
Total cost extends beyond per-token pricing because agents generate multiple rounds of tokens. Planning might use 5,000 tokens, each tool execution 500-1,000 tokens, result interpretation 500-2,000 tokens, and multi-step agents might iterate 3-10 times. A single user request can consume 20,000-100,000 tokens. This means a model costing
What does the data reveal about which industries are most adopting agents?
Customer support and automation show the highest adoption because helping customers and answering questions are natural agentic workloads. Data processing and analytics also show strong adoption where agents handle ETL and pipeline automation. Business process automation is emerging as companies automate approvals and expense processing. Healthcare and finance lag due to regulatory concerns about liability. Geographic variation exists too—U.S. companies favor frontier models, Europe emphasizes open-source and self-hosting, and China is ahead on cost-optimized agentic efficiency.
How should companies think about latency when deploying agents?
Agent latency depends on task complexity and use case requirements. Simple agents might complete in 5-10 seconds while complex multi-step agents take longer. This is acceptable for conversational agents where users expect processing time and for background automation where latency doesn't matter. However, real-time applications requiring sub-second responses aren't suitable for complex agentic loops. Companies should match agent architecture to latency requirements rather than forcing agents into every scenario.
What does token consumption at 1 trillion per day tell us about the AI market?
Processing 1 trillion tokens daily represents extraordinary scale—it exceeds the monthly usage of many SaaS platforms. For context, this means agents and complex agentic flows are consuming a significant portion of global AI inference capacity. It demonstrates that agent adoption is already material enough to affect infrastructure decisions at scale. It also reveals that the market has already reached a phase where operational questions (SLAs, reliability, cost optimization) matter more than feasibility questions.
Related Topics for Further Exploration
As you deepen your understanding of AI agents and their production deployment, consider exploring these complementary areas: advanced agent architecture patterns including hierarchical and decentralized agent systems, prompt engineering techniques specifically for agentic workflows, building reliable multi-step automation with error recovery mechanisms, cost optimization strategies for large-scale agent deployment, and emerging regulatory frameworks governing autonomous agent decision-making in sensitive industries.
The Path Forward
The data from Open Router processing 1 trillion tokens daily settles one question definitively: AI agents are no longer experimental. They're in production systems handling real business logic, making real decisions, and generating real revenue impact.
The tool call explosion, the SLA inflection point, the dominance of reasoning tokens—these aren't signs of a trend. They're confirmation of a fundamental shift in how AI is being deployed.
The question now isn't whether agents are ready. The question is whether you're building for a future where agents are central, or whether you're still optimizing for a world that's already changing. The infrastructure data makes the answer clear.

Key Takeaways
- Tool call rates exploded from under 5% to over 25% in 12 months, proving agents are now in production, not just experimentation
- The July 2024 inflection point marked when customer conversations shifted from feature evaluation to SLA negotiation, indicating genuine business dependency
- Reasoning tokens grew from zero to 50% of output in 13 months, as companies invest more compute in model thinking for reliability
- Production architecture pattern is emerging: frontier models for planning, smaller open-weight models for execution, reducing costs by 70-80%
- Chinese open-weight models are capturing unexpected market share in U.S. agent deployments due to superior tool-execution reliability and lower costs
- Unit economics of agents are critical: single tasks consume 20,000-100,000 tokens, making optimization essential for viability
- Customer support and data processing lead agent adoption; healthcare and finance lag due to regulatory liability concerns
- SLA requirements have become standard for production agents, indicating the shift from prototype to critical infrastructure phase
Related Articles
- Google Gemini 3.1 Pro: AI Reasoning Power Doubles [2025]
- Facial Recognition Goes Mainstream: Enterprise Adoption in 2026 [2025]
- India's Sarvam Launches Indus AI Chat App: What It Means for AI Competition [2025]
- AWS 13-Hour Outage: How AI Tools Can Break Infrastructure [2025]
- Can We Move AI Data Centers to Space? The Physics Says No [2025]
- G42 and Cerebras Deploy 8 Exaflops in India: Sovereign AI's Turning Point [2025]

